2025年7月14日,TOPS第166期组会于通达馆A102线下举行。本次组会由20级博士邱树涵与大家交流讨论《数据-知识融合驱动的路径选择行为建模研究》的相关内容。课题组全体老师同学出席了本次组会。

汇报时刻
邱树涵同学从研究背景、现有工作介绍、研究内容、研究总结等四个方面对他的研究《数据-知识融合驱动的路径选择行为建模研究》展开介绍。
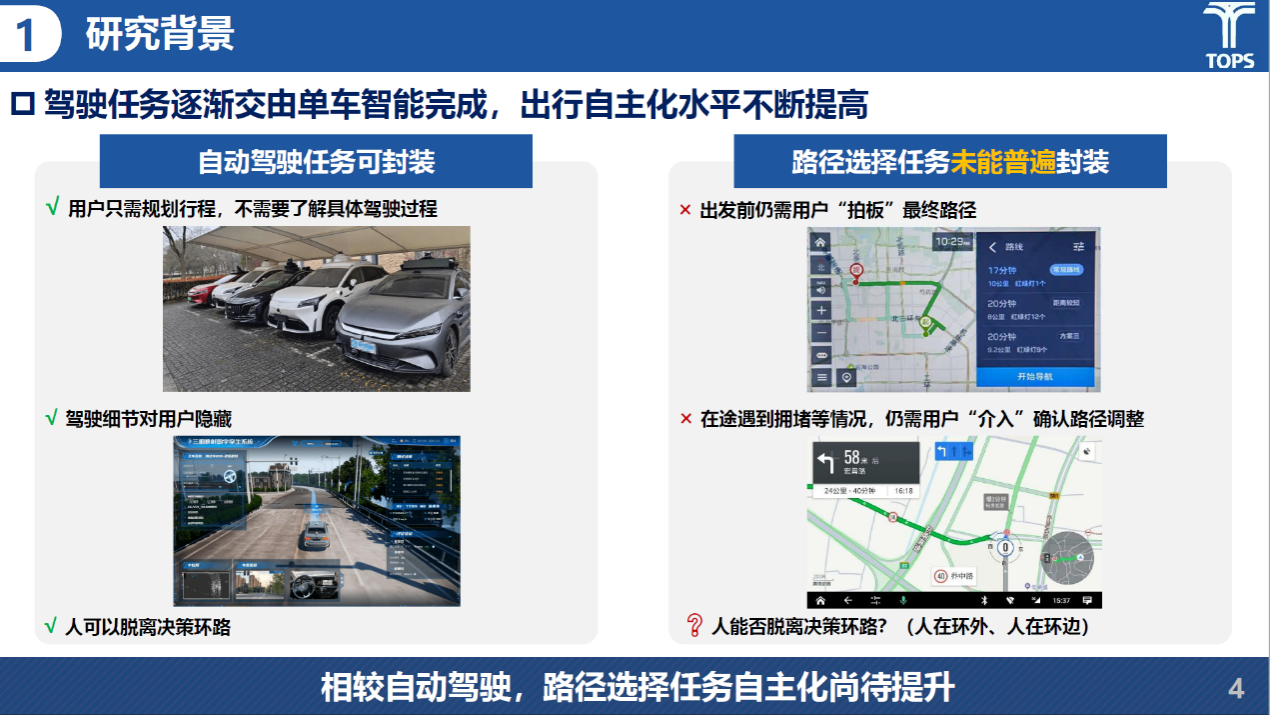
在研究背景上,邱树涵提到出行自主化水平不断提高,路径选择仍需用户参与,如出发前确定路线、途中调整路径,驾驶员尚未完全脱离决策。需要深入研究出行者偏好(路径选择行为建模)和系统状态(路径重构/推演)的高阶表征。
研究内容
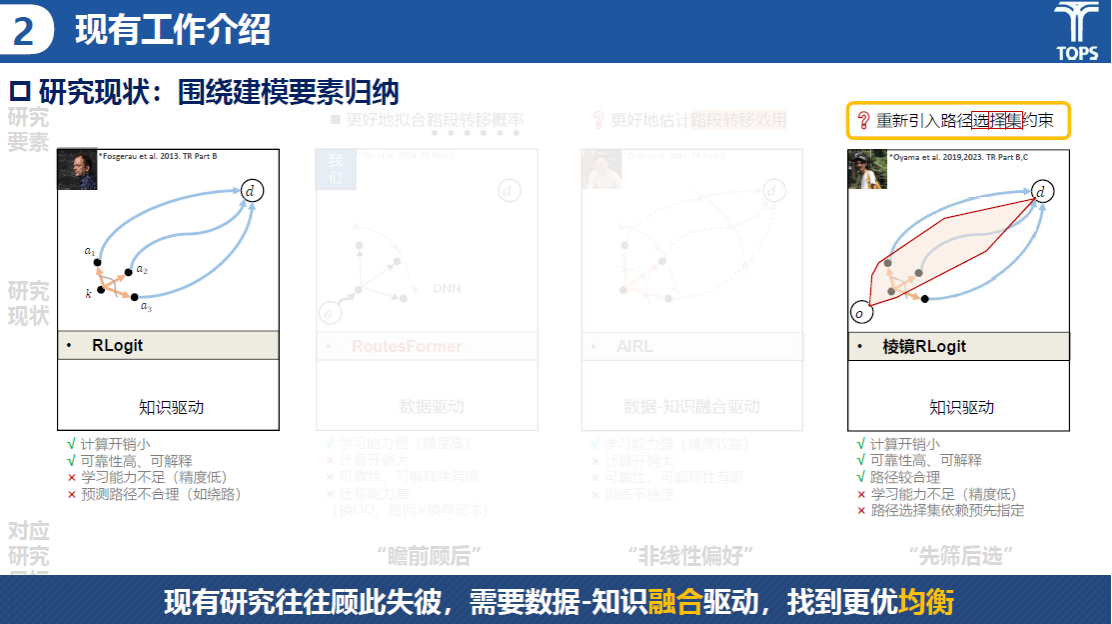
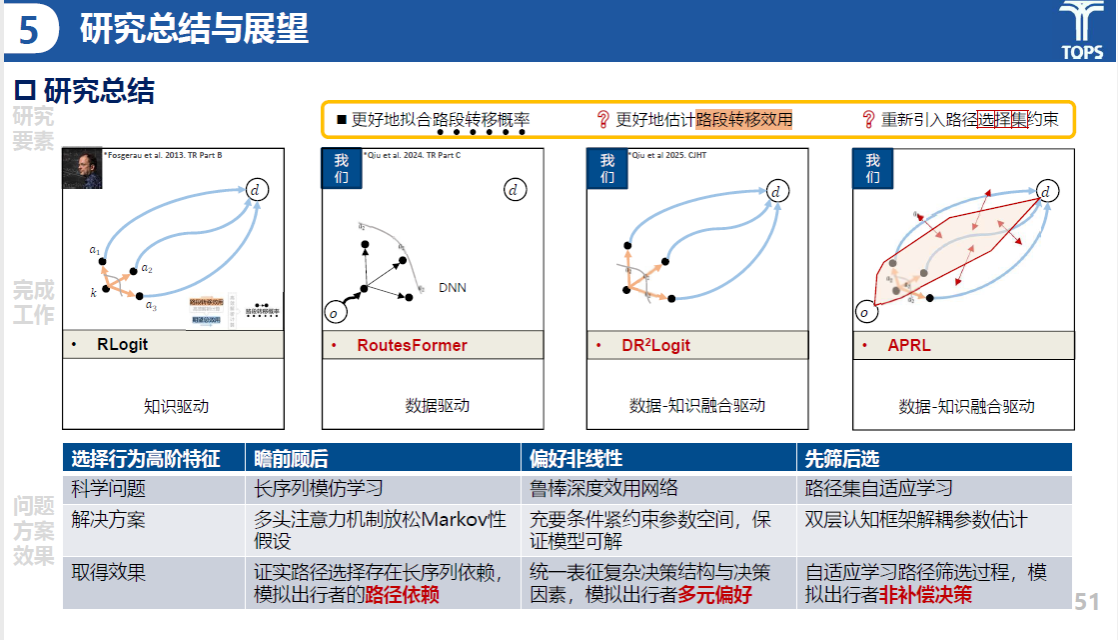
邱树涵同学在研究现状板块,围绕着建模要素进行了要素归纳。总结了RLogit、RoutesFormer、AIRL和棱镜RLogit等四种路径选择方法的研究现状,发现其在不同方面存在局限,亟需通过数据与知识的融合驱动,以提升路径选择的准确性与实用性。
研究内容
在研究总览上,RLogit 是路径选择建模的重要基础,便于建模与推导,易于与其他模型融合,具备良好的可扩展性。为更好刻画复杂的非线性偏好,可尝试将 RLogit 的效用函数深度化。该问题的关键挑战在于求解不稳定,在训练过程中可能会出现误解或发散的情况,根源在于参数空间缺乏合理约束。因此,修复求解鲁棒性不足的问题,是效用深度化表征的前提。

研究内容
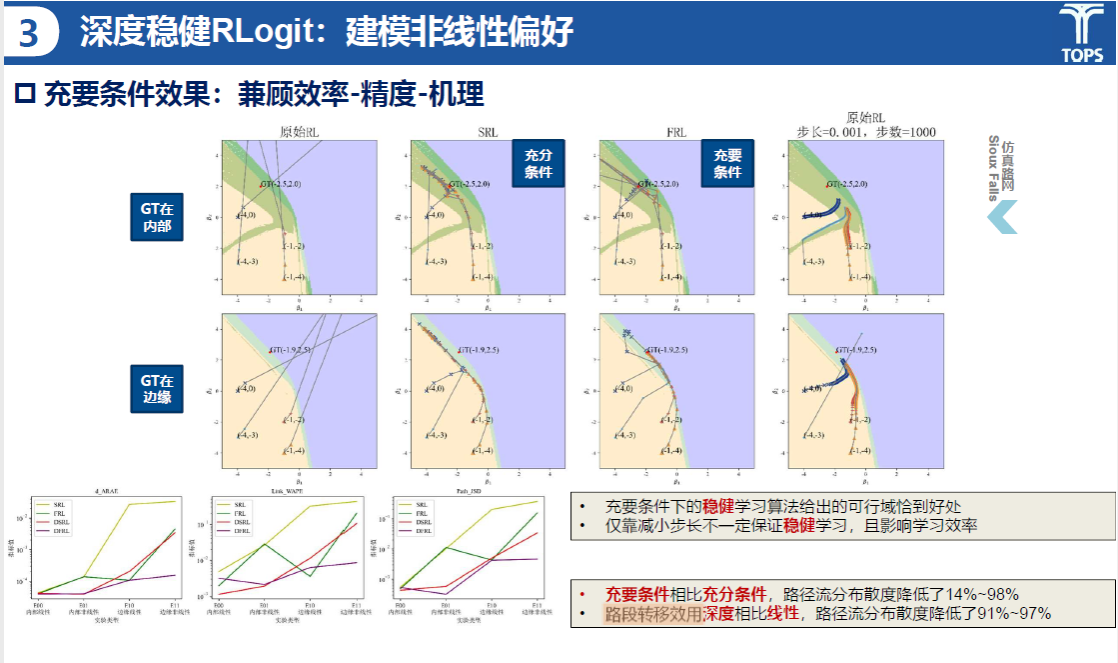
深度稳健Rlogit模型用于刻画复杂的非线性偏好,兼顾效率、精度和机理。通过对比不同方法(SRL, FRL)在不同条件下的表现,说明了深度稳健RLogit在处理复杂非线性问题时的优势。充要条件下的稳健学习算法给出的可行域恰到好处,仅靠减小步长不一定保证稳健学习,且影响学习效率充要条件相比充分条件,路径流分布散度降低了14%~98%,路段转移效用深度相比线性,路径流分布散度降低了91%~97%。
研究内容
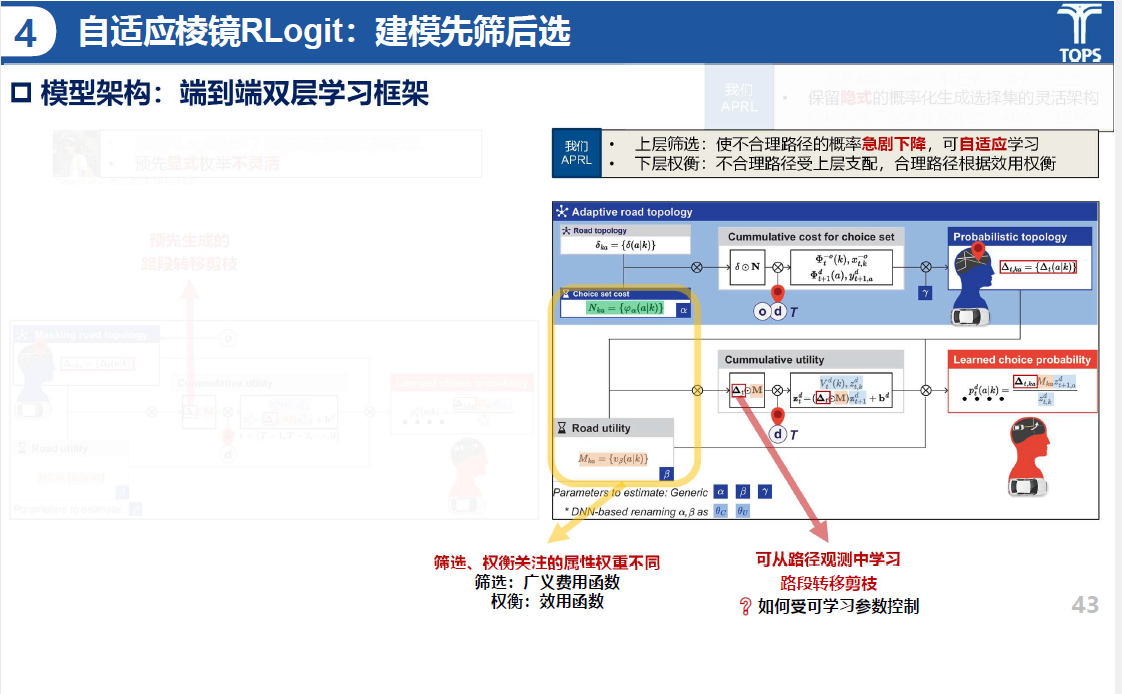
自适应棱镜Rlogit模型采用建模先筛后选的方式,模型架构为端到端双层学习框架,上层筛选:使不合理路径的概率急剧下降,可自适应学习;下层权衡:不合理路径受上层支配,合理路径根据效用权衡。
研究内容
在下一步工作计划上,邱树涵同学将继续以路径重构/推演为目标,推进路径选择模型(DR⟡Logit、LLM-DR⟡Logit、APRL)在系统任务的部署;建模定点稀疏观测信息,并利用模型补全历史、预测未来。
研究内容
老师和同学们针对邱书涵同学的研究,在出行行为建模方向的研究需求与研究方向,模型结构的设计问题、效用计算公式等方面的问题进行了讨论。同门们也提出了一些宝贵的建议和改进意见,希望在后续研究中继续深化和完善,取得更加丰硕的成果。
电话:021-69583650 管理员邮箱:2015qgy@tongji.edu.cn
地址:上海市曹安公路4800号同济大学交通运输工程学院A440 邮编:201804
![]() TOPS课题组 页面浏览465,829次/访客70,123人次
TOPS课题组 页面浏览465,829次/访客70,123人次
{kind=link}