2025年4月2日,TOPS第159期组会于通达馆A102线下举行。本次组会由23级硕士黎瑞和22级硕士刘佳琦与大家交流讨论《基于博弈论的自动驾驶最优社会性研究》和《基于Transformer模型的自动驾驶自进化决策研究》的相关内容。课题组全体老师同学出席了本次组会。

汇报时刻
黎瑞同学从研究背景、演化博弈论研究、驾驶行为演化研究和多车对抗赛研究四个方面展开介绍。
研究背景部分黎瑞同学提到,现阶段的自动驾驶往往过于保守,从而导致对道路安全和商业运营产生负面影响,需要进一步聚焦优化自动驾驶策略,提升自动驾驶表现。
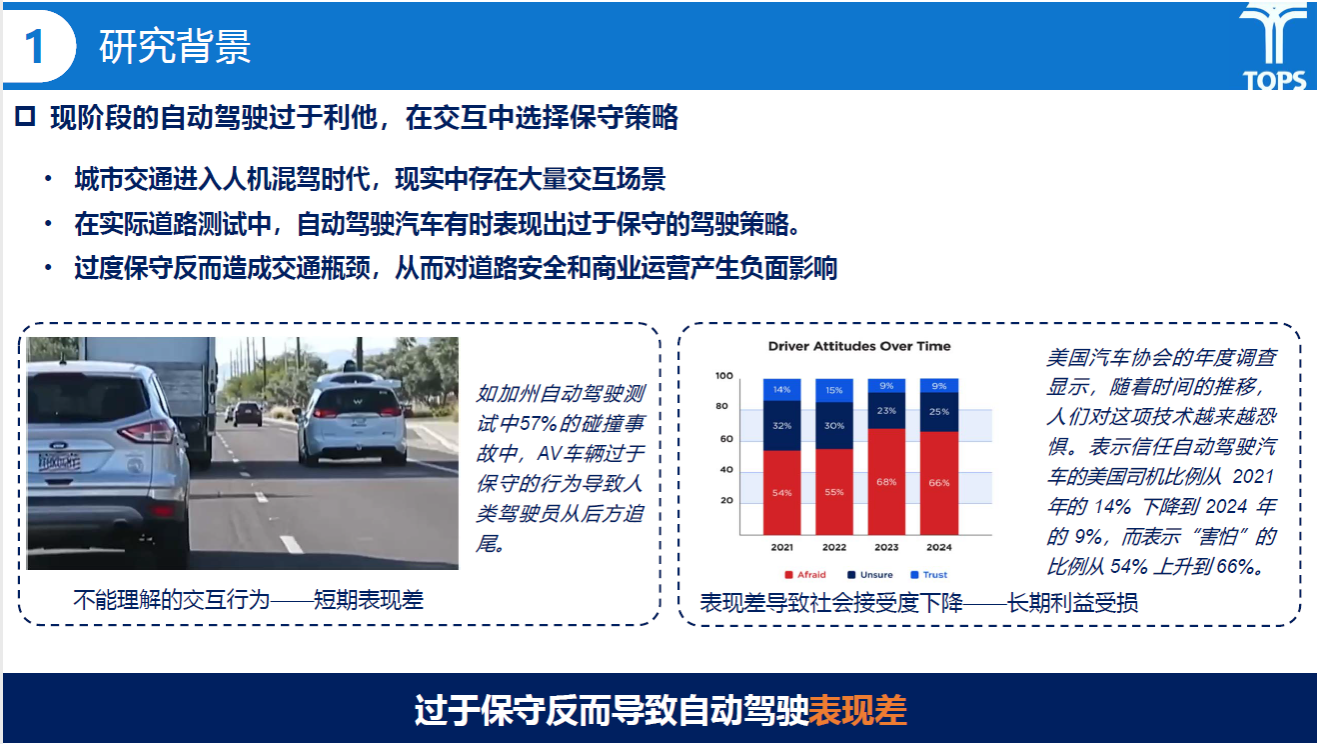
研究内容
随后,黎瑞同学介绍了其研究的技术路线与内容。研究内容主要围绕基于演化博弈论的最优社会性推导、基于驾驶行为演化分析的交互事件中的行为偏移观测与基于多车循环对抗赛实验分析三部分展开。
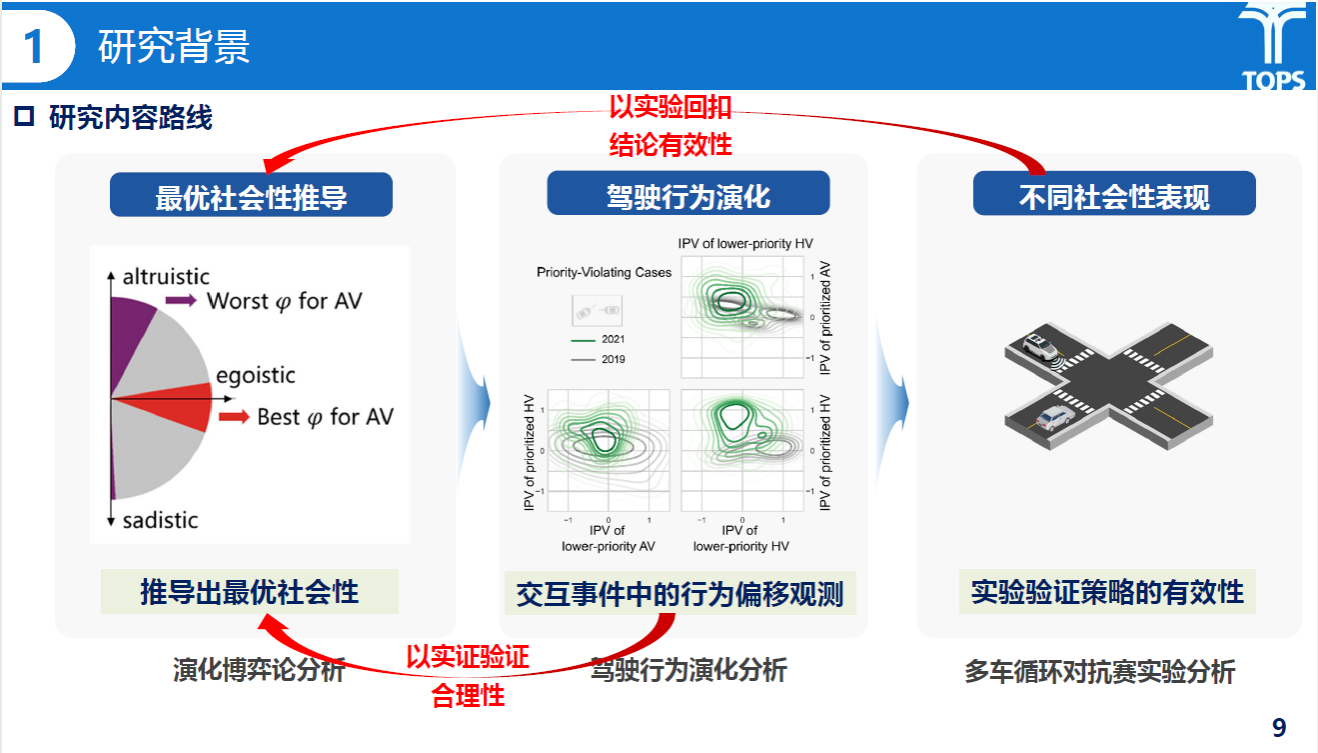
研究内容
演化博弈论研究部分主要基于无保护左转交叉口场景建立非对称演化博弈模型。该部分通过Argoverse2数据集提取交互事件,并对不同交互事件的轨迹进行标定以得到不同社会倾向AV的权重,依次遍历最后计算推导可得博弈稳定均衡解,最后对稳定均衡解、演化趋势等方面进行了相关分析。

研究内容
驾驶行为演化研究作为实证部分为演化模型提供支撑。该部分工作采用IPV指标对Argoverse2数据集中的交互行为进行标定;并随机选取交互事件进行迭代仿真,分析不同社会性组合下的演化趋势,并引入高斯白噪声模拟博弈参与者策略选择上的认知误差与外部扰动。
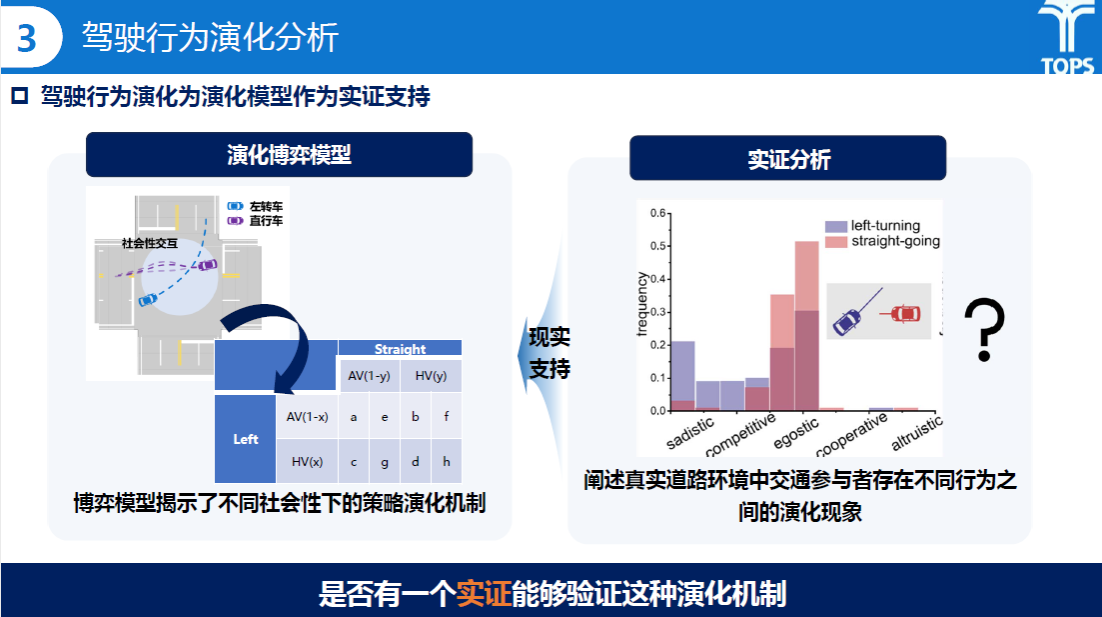
研究内容
多车循环对抗赛部分灵感来源于重复的囚徒困境。该部分从OnSite平台选手的算法出发,修改了平台回放测试的接入机制与动态场景文件,使得测试可以接入多辆主车;后续计划以选取规控算法进行多车对抗、重复交互过程迭代收敛域多重维度分析等步骤展开。

研究内容
接着,刘佳琦同学从研究背景、研究内容、实验分析与研究总结等四个方面对他的研究《基于Transformer模型的自动驾驶自进化决策研究》展开介绍。
研究背景部分,刘佳琦同学提到当前基于规则的传统决策系统存在ODD碎片化、算法适应性差等问题,自动驾驶决策系统需要具备自进化与持续学习能力。而如今,大模型由于其泛化能力和通用性已成为实现L4级自动驾驶的最重要技术路线之一,同时预训练+微调的方式已经成为大模型持续学习和效果提升的重要手段,其可帮助提升数据驱动的自动驾驶决策算法的泛化能力。
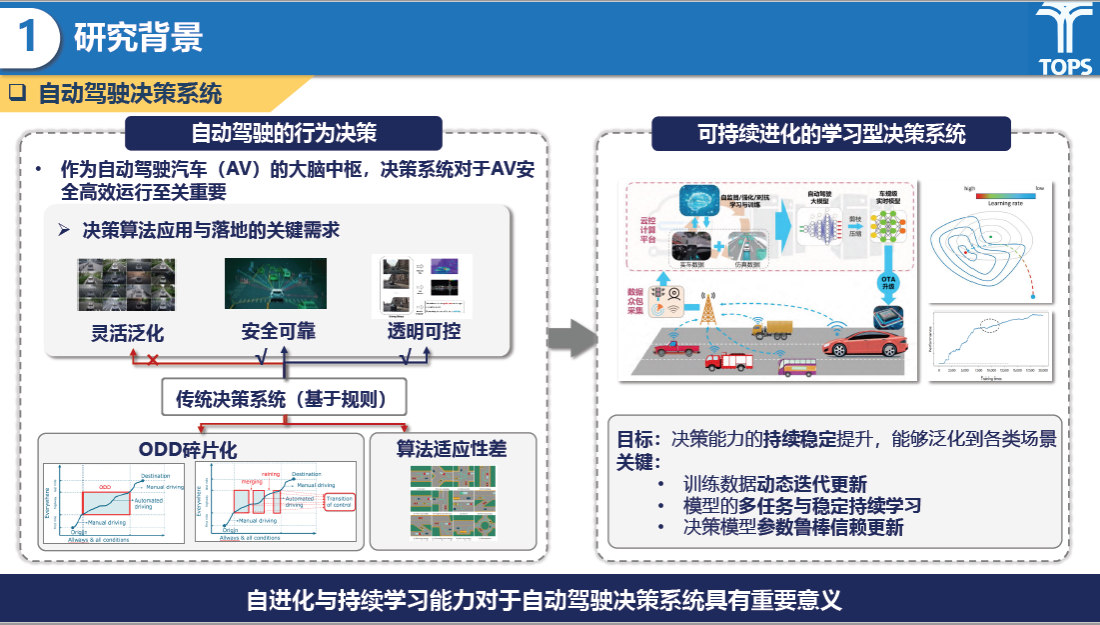
研究内容
随后,刘佳琦同学介绍了主要的研究内容,包括基于专家策略采样的专家数据集构建、基于自回归序列建模的GPT模型离线训练、基于熵正则和策略微调的GPT模型在线自进化与实验验证等内容。
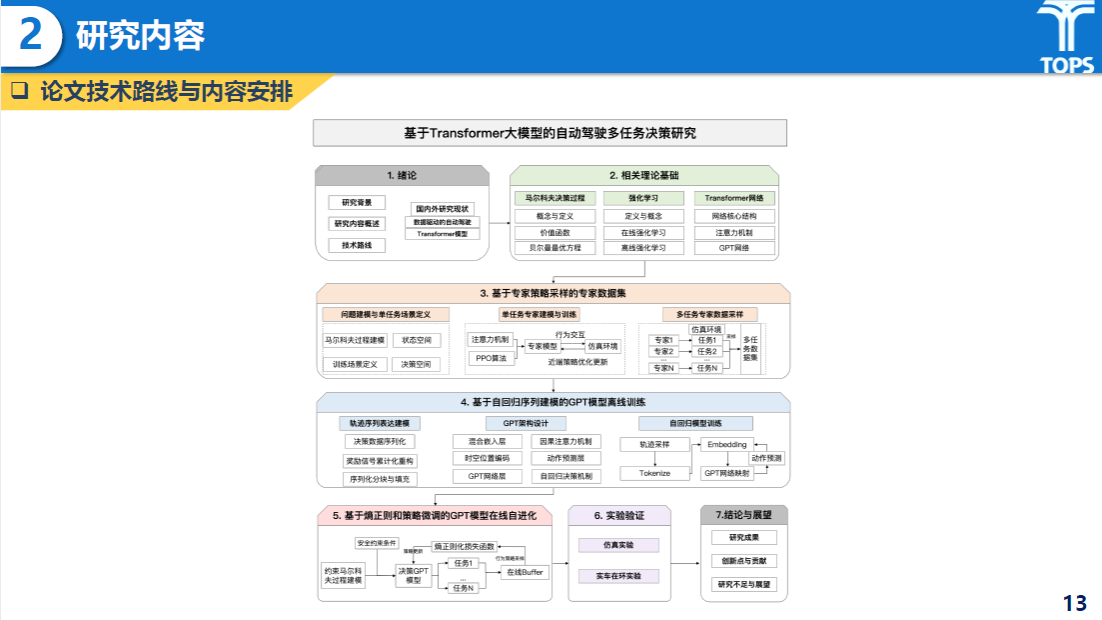
研究内容
基于专家策略采样的专家数据集构建部分主要提出了一种“先分后合”的策略,首先在多个决策子任务上分别训练强化学习专家模型(Expert Policies);然后利用这些专家策略作为教师(Teacher Policies)收集高质量演示数据;最终构建一个多任务离线数据集,为决策GPT模型预训练提供坚实基础。
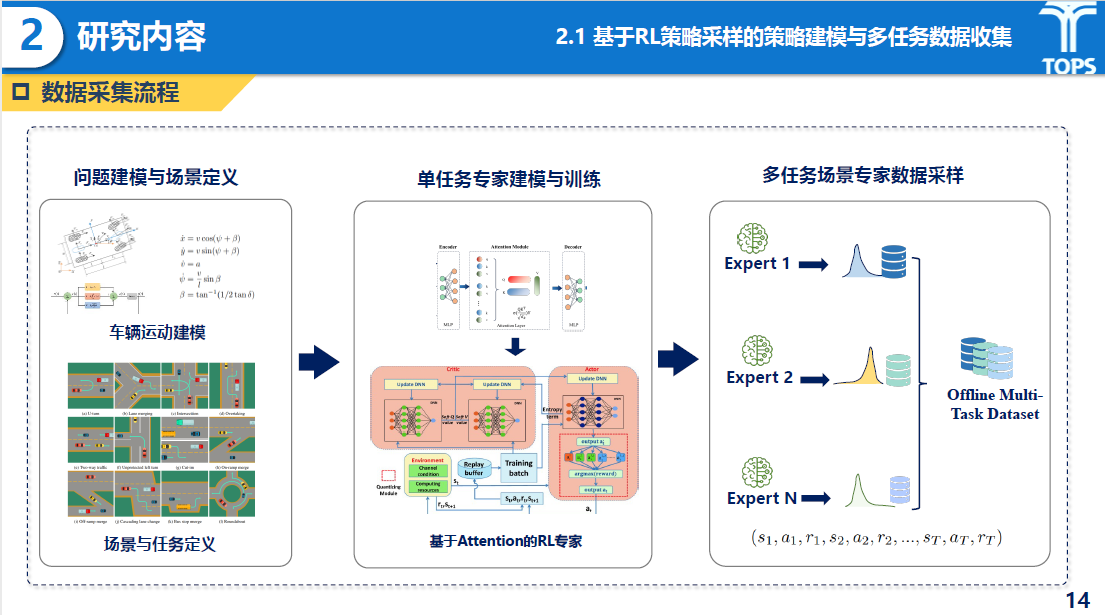
研究内容
基于自回归序列建模的GPT模型离线训练部分主要提出了一种基于GPT-2作为基础结构、通过交叉熵损失函数完成多任务预训练的方法。
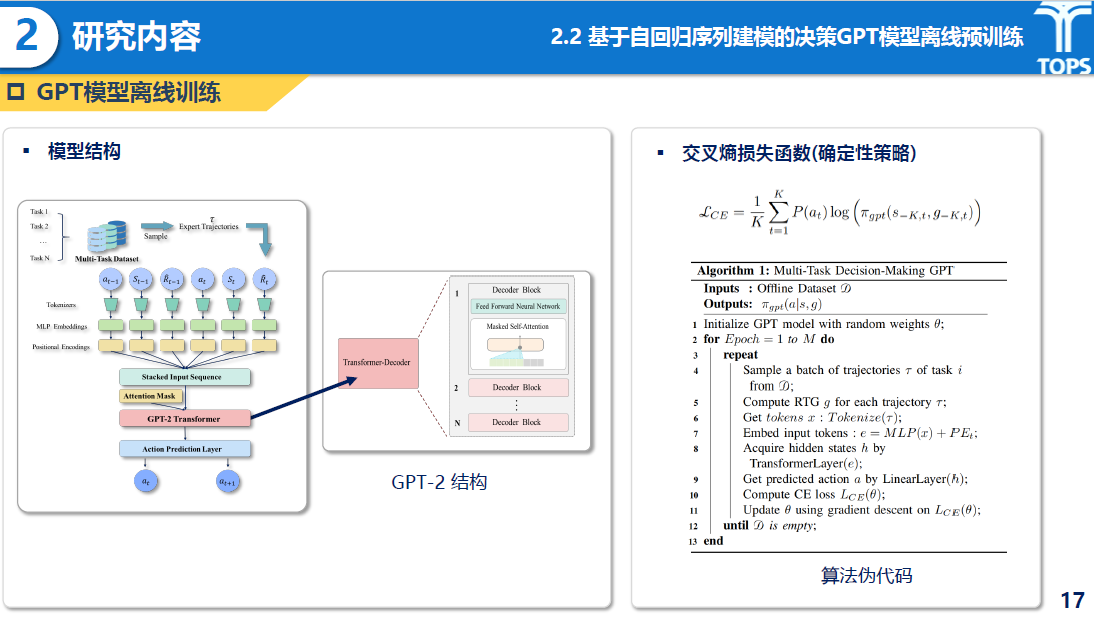
研究内容
基于熵正则和策略微调的GPT模型在线自进化部分主要通过引入熵正则项,并将传统MDP升级为约束马尔科夫决策过程(CMDP),建立在线策略更新流程,实现模型对未知任务的适应与性能提升。
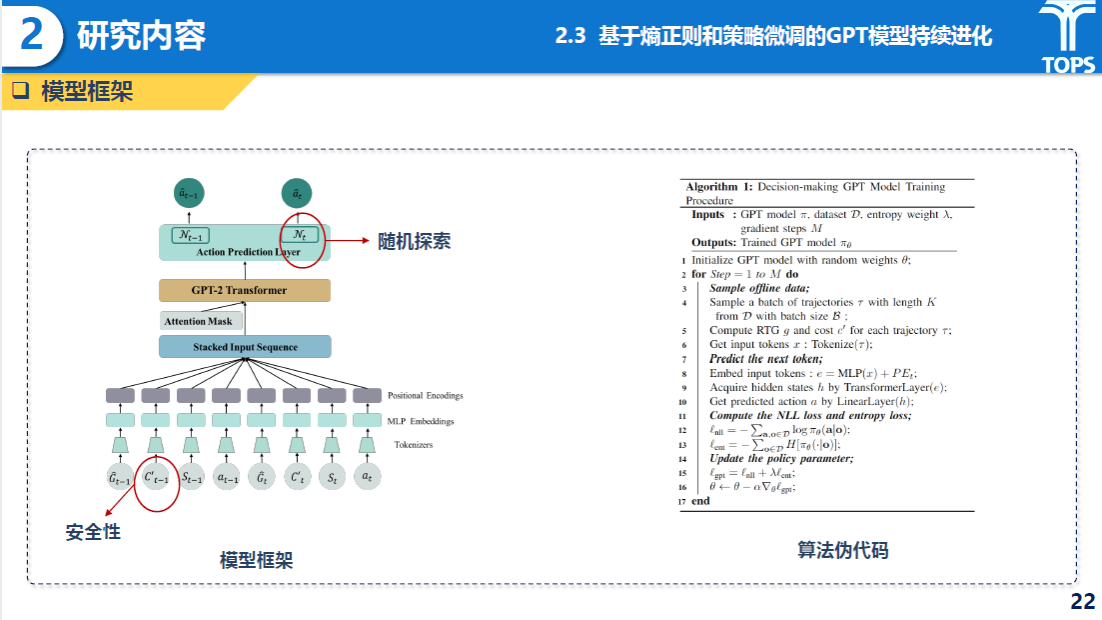
研究内容
实验部分主要包括决策GPT模型预训练实验、基于微调的在线更新实验与实车在环实验三部分。
其中,离线预训练实验结果表明,在多个子任务(左转、右转、直行)上训练的RL专家表现优于传统DQN、PPO算法,MTD-GPT在多个任务上逼近或超过RL专家性能。

研究内容
在线微调实验中,MTD-GPT在不同场景下平均奖励显著优于基线方法,安全成本显著降低;在线微调后模型持续提升性能,有效缓解预训练“风格冲突”和“灾难性遗忘”问题。
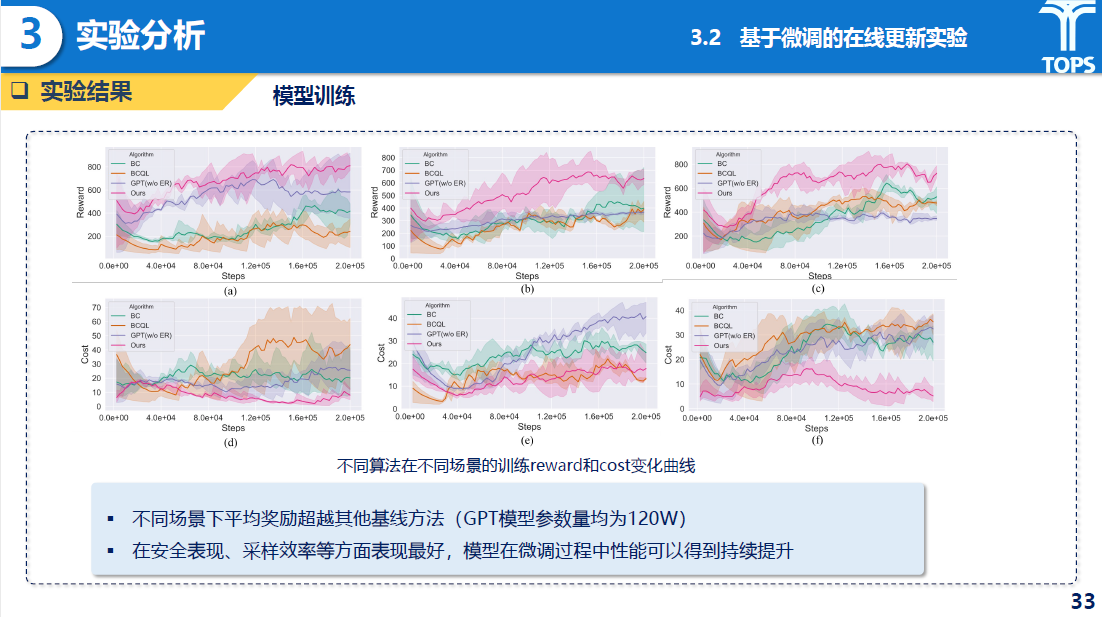
研究内容
实车在环实验中,实验选择同济自动驾驶测试区构建实车同步仿真系统,验证在交叉口无保护左转场景下的实际表现。实验表明模型的决策稳定性与安全性,进一步验证了线上模型到实际部署的可迁移性。
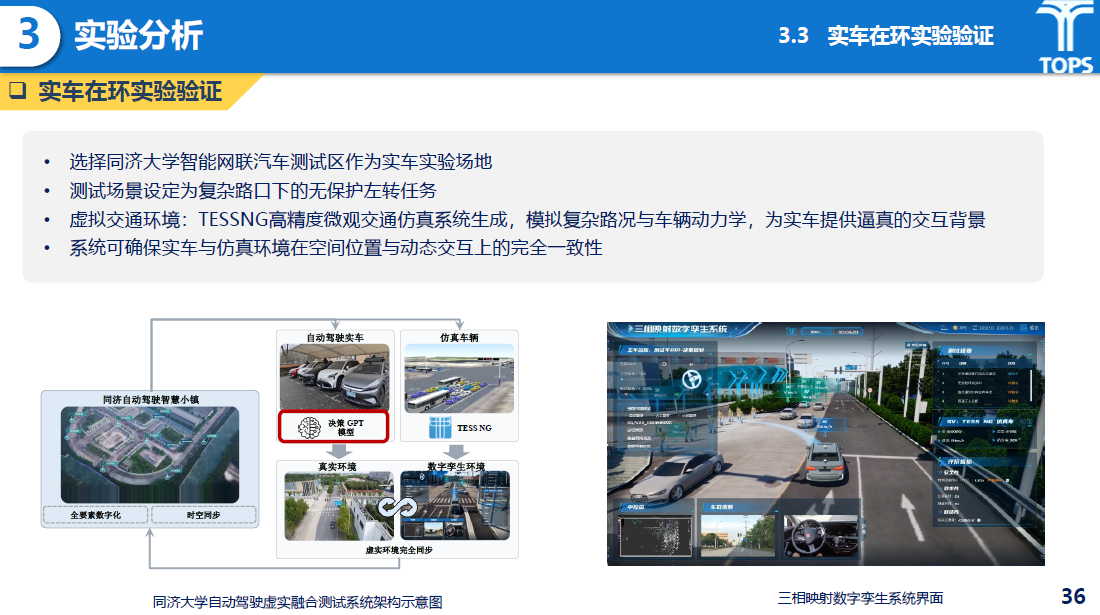
研究内容
在两位同学的研究分享之后,课题组的老师和同学们进行了深入的交流探讨。
针对黎瑞同学的汇报,刘林坤同学就演化博弈的最优结果与社会规则的相合性等方面提出了疑问;叶轶淳同学就无保护左转场景建模结论的泛化性提出了疑问;冯华越同学就OnSite平台接入多辆主车的场景异常现象提出了疑问;刘学凯同学针对演化趋势的分析结果提出了疑问;房世玉同学针对演化趋势分析的结论提出了疑问;吕志超老师针对高斯白噪声添加等方面提出了疑问,并强调了该方面可以增加说服力;倪颖老师针对最优社会性里“最优”的定义提出了疑问;孙剑老师从汇报整体的时间把控、研究背景、部分定义与概念的介绍进行了建议,并提出可增加受控实验捕捉问题关键,考虑逆向思维给AV自进化提出建议等细节方面的建议。
针对刘佳琦同学的汇报,房世玉同学就训练的错误累积、信息泡沫等问题提出了疑问;叶轶淳同学就TOKEN变化、点云数据输入等问题提出了疑问;刘学凯同学就模型输入等方面提问了疑问;杨宇豪同学就模型训练时的数据编码等细节提出了疑问。最后,孙剑老师肯定了该研究的技术含量,同时也指出大论文闭环等关键问题。并提出可以从OnSite场景库出发去测评实际效果,指出未来可以朝算测一体化方向去钻研。田野老师指出汇报时给的主题范围过大,需要进一步凝练、着重强调与主题的相关字眼等问题。
电话:021-69583650 管理员邮箱:2015qgy@tongji.edu.cn
地址:上海市曹安公路4800号同济大学交通运输工程学院A440 邮编:201804
![]() TOPS课题组 页面浏览465,829次/访客70,123人次
TOPS课题组 页面浏览465,829次/访客70,123人次
{kind=link}