2024年7月24日下午16:30,TOPS第147期组会于通达馆A102线下举行。本次组会由21级博士生王诗菡带来自己的研究进展汇报,与大家讨论交流《面向自动驾驶测试的复杂交互行为策略仿真》的相关内容。课题组全体同学出席了本次组会。
 汇报时刻
汇报时刻
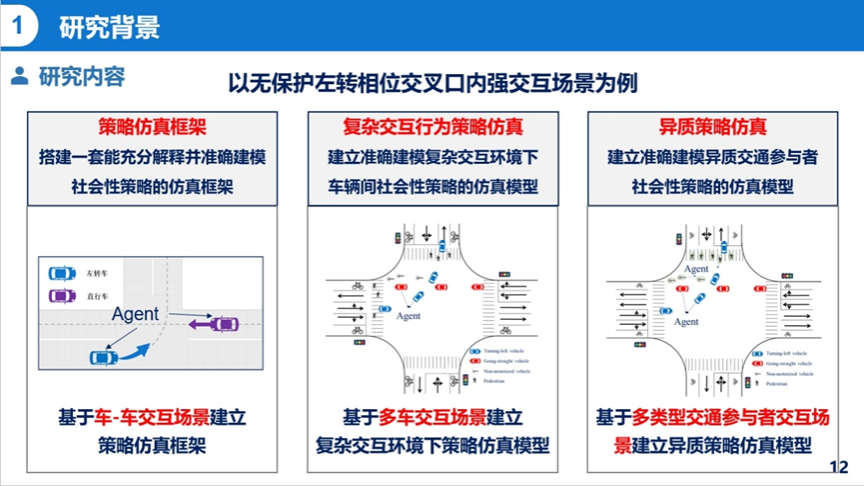
本次汇报从研究背景与内容、基于MA-AIRL的车-车交互行为策略仿真-基于social-MAIL的多车交互行为策略仿真、总结与展望四个部分展开。王诗菡首先从现实问题切入,介绍了自动驾驶虚拟仿真测试与AV社会交互能力测试的现实需求。在背景中指出现有的机理驱动模型难以复现复杂交互行为,而数据驱动模型难以准确解释并建模上层动态交互策略,对不同交通参与者之间的行为异质性考虑不足,从而引出了研究目标:搭建一套能充分解释并准确建模复杂交互环境下异质交通参与者社会性策略的仿真框架。
 汇报内容
汇报内容
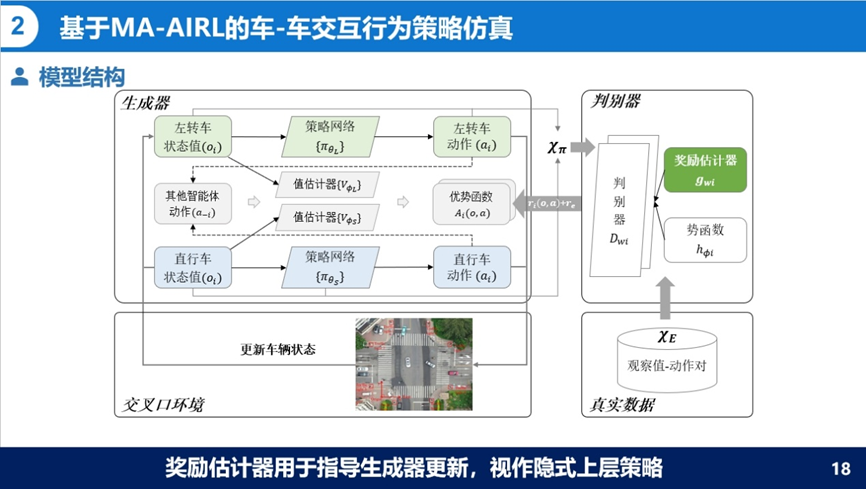
接着介绍了基于MA-AIRL的车车交互行为策略仿真。驾驶交互行为被视为马尔科夫博弈过程,每辆车都是一个决策智能体;模型结构包括生成器和判别器两部分,其中判别器学习奖励函数,生成器利用判别器学习得到的奖励函数学习生成更优车辆轨迹;采用SIND数据集对模型进行训练,并从交互策略和轨迹准确度两部分对模型做出评价,模型生成场景的整体交互决策准确度为100%,轨迹的均方根误差为3.07m,速度和角度的JS分别为0.12和0.08,轨迹准确度提升了21%。
 汇报内容
汇报内容
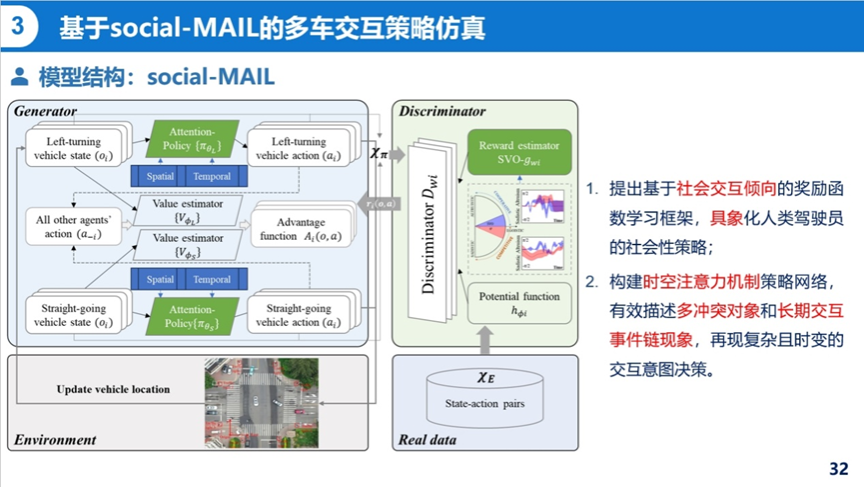
接着介绍了基于social-MAIL的多车交互行为策略仿真。现有的隐式策略仿真模型在多车复杂交互环境下的解释性弱,难以定向为AV提供测试场景,且仿真轨迹精度较低,因此提出基于社会交互倾向的奖励函数学习框架,具象化人类驾驶员的社会性策略。构建了时空注意力机制策略网络,有效描述了多冲突对象和长期交互事件链对象,再现复杂且时变的交互意图策略。同样从交互策略和轨迹准确度两部分对模型进行评价,在训练和测试场景中模型的准确率分别达到了74%和70%,在捕捉交通场景中的基本交互行为方面非常有效。
 汇报内容
汇报内容
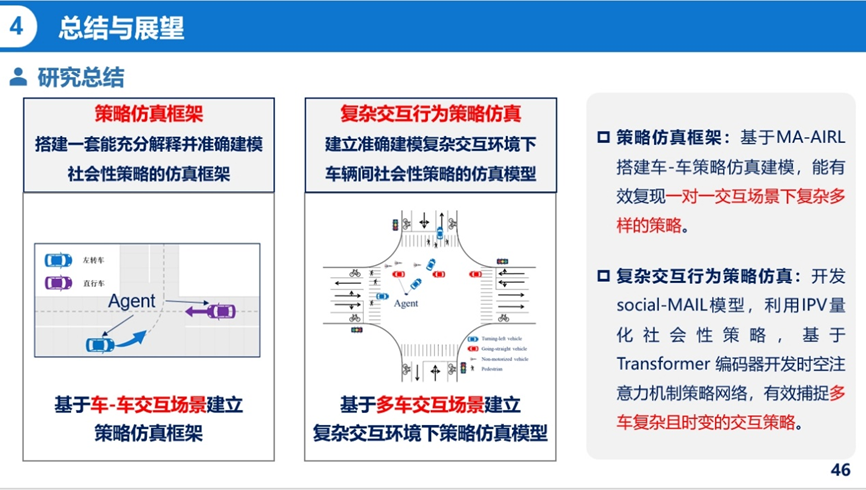
最后王诗菡对研究内容进行总结与展望。

汇报内容
在交流讨论环节,课题组各位同学提出了对此次汇报进行了提问和建议。
至此,本次组会圆满结束。
电话:021-69583650 管理员邮箱:2015qgy@tongji.edu.cn
地址:上海市曹安公路4800号同济大学交通运输工程学院A440 邮编:201804
![]() TOPS课题组 页面浏览465,829次/访客70,123人次
TOPS课题组 页面浏览465,829次/访客70,123人次
{kind=link}