2026年4月9日,TOPS第179期组会于通达馆A102线下举行。本次组会由26级博士叶轶淳进行《拉马克驾校:自动驾驶的进化式训练策略》主题的学术报告分享。课题组全体老师同学出席了本次组会。

汇报时刻
在研究背景方面,叶轶淳同学指出,当前自动驾驶训练已从依赖自然驾驶场景转向利用场景生成方法构建大规模场景库。然而,自然驾驶场景存在高危险、长尾分布和不确定性等困难,导致训练效果差、效率低。虽然生成的场景数量多、难度高,但其场景价值模糊,难以匹配训练需求,容易引发分布偏差、不可解难题甚至灾难性遗忘,使得训练场景本身成为制约自动驾驶发展的瓶颈。
进一步地,业界存在加速训练、突破算法能力边界和实现零样本泛化三大现实需求,这凸显了当前训练策略的不足。现有的主流方法,如课程学习和对抗学习,虽各有侧重,但课程学习本质上仍在已知分布内采样,难以突破算法上限;而对抗学习则易出现分布极化,导致泛化能力下降。因此,现有方法在训练效率、充分学习和泛化能力上均未达成理想效果,亟需探索能够兼顾效率、能力与泛化的最优训练策略。

研究背景
基于此,叶轶淳同学提出了构建“拉马克驾校”进化式训练策略的研究思路,旨在将自然进化论的“优胜劣汰、用进废退”思想引入自动驾驶训练,通过双向进化的双层优化框架,实现对训练环境的持续搜索与自动驾驶策略的协同进化,从而推动训练过程由“单环境经验主义”到“多环境课程递进”,再到“全环境适者生存”的转变,实现高价值训练环境和算法最优策略搜索的协同进化闭环。
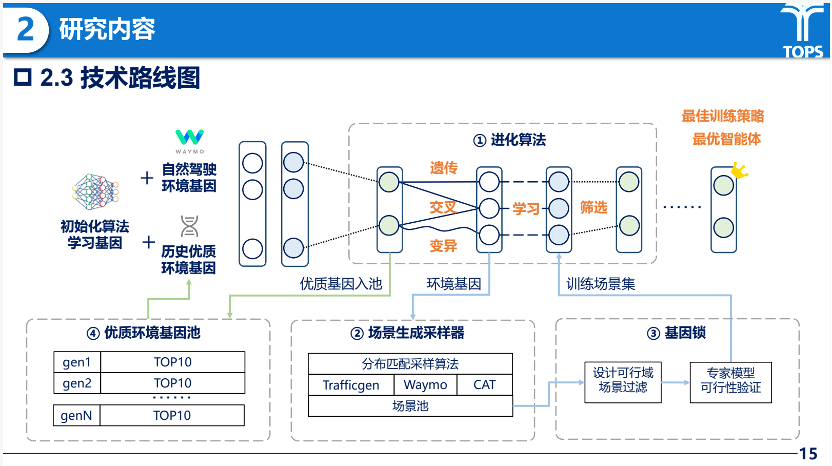
技术路线
在研究内容方面,叶轶淳同学围绕“拉马克驾校”进化式训练策略,构建了一个由双层优化驱动的协同进化框架。其核心是以改进的遗传算法为驱动引擎,通过遗传、交叉、变异、学习和淘汰五类操作模拟优胜劣汰过程,持续筛选高效的环境与策略组合。同时,场景生成与采样模块负责将抽象的环境参数分布转化为具体训练数据,采用自然驾驶数据、泛化生成器与对抗生成器三源混合的构建方式,确保环境搜索结果能够切实落地为高质量的训练场景集。
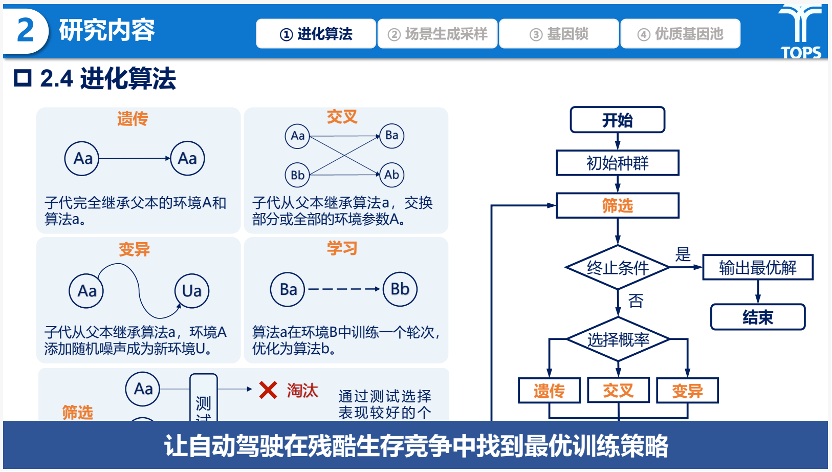
研究内容
在此基础上,框架引入基因锁机制以保障训练素材的有效性,通过ODD规则约束剔除物理无效场景,并借助具备全局信息的专家验证筛除不可解的极端样本。此外,优质基因池设计通过对历史进化中高效环境基因的保存与复用,使后续进化能以经验种子起步,从而显著加速搜索收敛并形成持续积累的策略知识库。
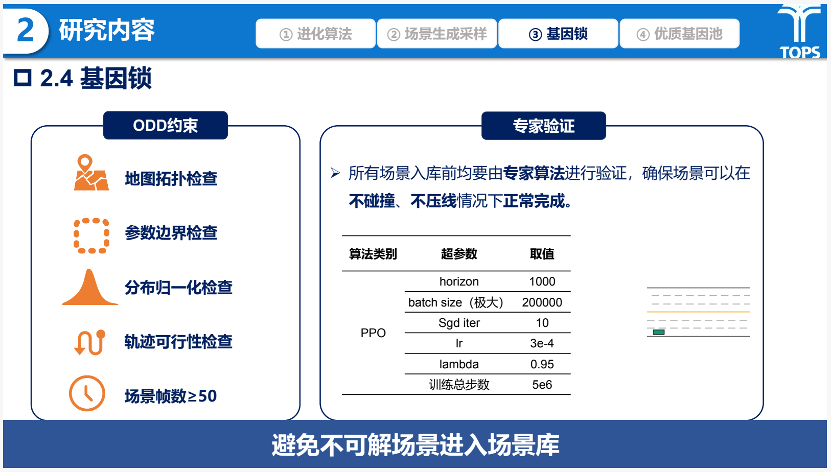
研究内容
上述模块相互耦合,共同构成了完整的协同进化闭环:进化算法统筹环境与策略的双向优化,场景生成与基因锁保障素材质量,优质基因池提供历史经验支撑。整个流程从初始策略与环境出发,经多轮迭代进化,最终输出最优驾驶策略及其对应的最佳训练环境序列,从而对“最优训练策略是什么”以及“好场景如何定义”这两个核心问题给出系统性回答。
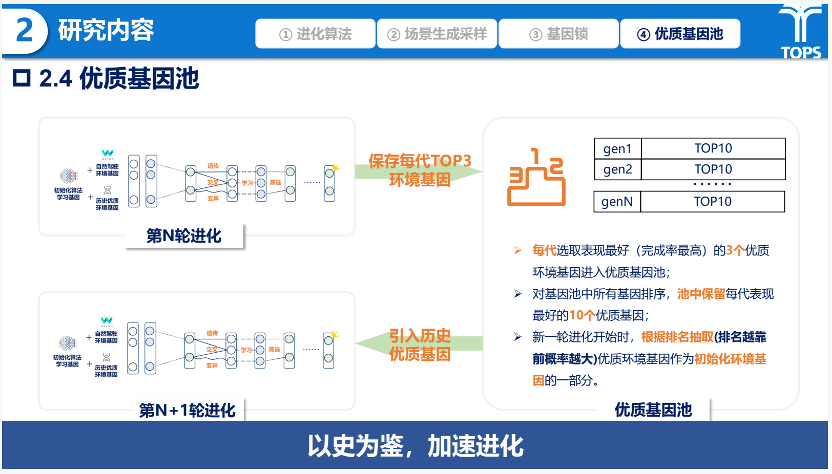
研究内容
在实验分析方面,叶轶淳同学基于MetaDrive闭环仿真平台,结合Waymo Open Motion Dataset重构真实交通场景,以TD3为决策算法、CAGE与TrafGen为对抗与泛化场景生成器,对“拉马克驾校”框架进行了系统评估。结果表明,在训练效率与能力上限方面,该方法在成功率、碰撞率及平均奖励上均显著优于自然驾驶、课程学习与对抗学习等基线方法,在Waymo测试集上任务未完成率降低56.7%、碰撞率降低55.83%,并实现20.9倍的训练加速。
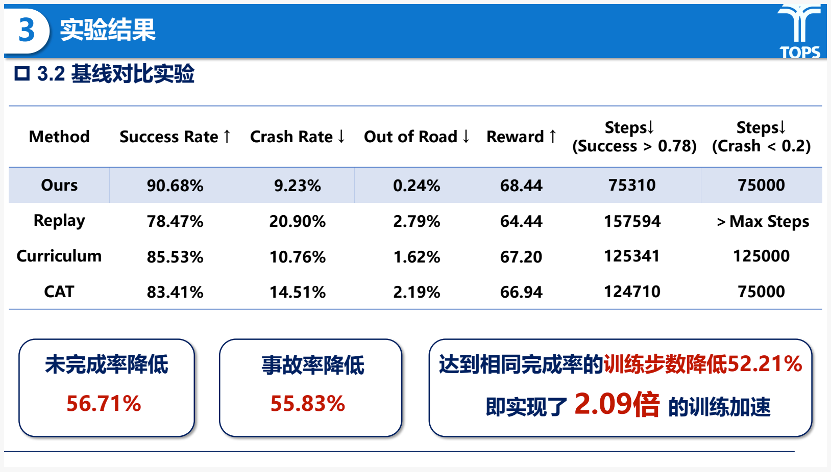
实验分析
在跨域泛化能力方面,当测试集更换为训练中未见过的nuScenes数据时,所提策略仍保持各项指标领先,未完成率降低33%、碰撞率降低17.9%,同时实现33.1倍的训练加速,显示出一定的泛化优势。
在演化过程分析方面,最优训练策略呈现明确的阶段性特征且与经典“由易到难”的课程学习思路差异显著:初期强调简单、集中且风险可控的场景以建立基本规则;中期迅速转向高难度、强交互场景以施加决策压力;后期则维持高难度下的场景多样化分布,包含大量复杂交互并适度保留中等及简单场景,这种“大杂烩”式分布是促进算法能力最终收敛与泛化的关键特征。
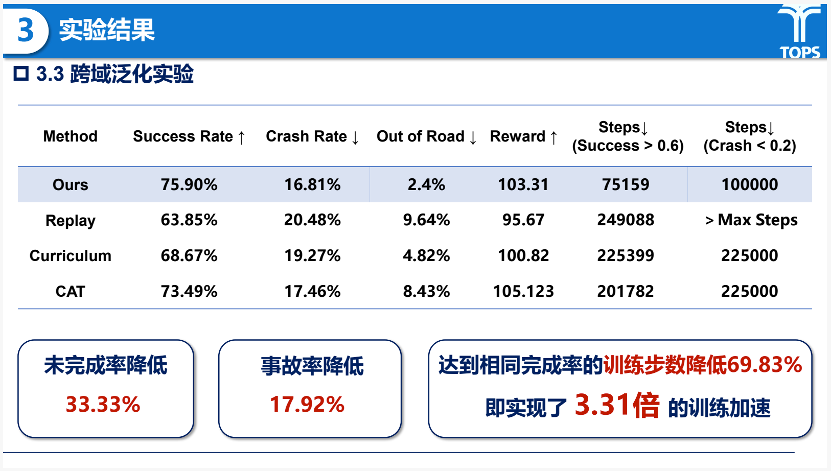
实验分析
未来,叶轶淳同学计划针对算法泛化性与计算成本等不足,通过引入跨域评价指标、验证最优策略的普适性、构建训练效果代理模型及优化场景条件生成,进一步探索并验证最优训练策略的通用价值。
汇报结束后,与会师生围绕研究内容展开了深入讨论。多位同学首先就实验结果统计可靠性、理论公式变量定义及算法泛化性设计提出了若干问题。随后,梁浩阳博士建议跨域评估应更多关注仿真到实车的迁移性,并指出通过调整背景车参数模拟不同驾驶行为可能比跨数据集更具可行性;秦国阳博士则围绕策略与环境的目标函数一致性提出疑问,认为当前全局目标函数F是对理想泛化空间的某种妥协,反映出对算法泛化能力底层逻辑的重视。
孙剑老师对研究提出了四项核心要求,强调必须注重横向可比性、解耦性以及面向企业实际需求的实用性,指出33倍训练加速若缺乏与行业标杆的充分对比便难以体现价值,并进一步追问了训练与测试闭环机制的具体界定问题。孙杰老师指出当前训练方案的真实成本可能被低估,建议通过构建通用价值场景来适配不同算法以避免重复进化过程,从而提升整体效率。杭鹏老师则建议小论文阶段应进一步聚焦具体问题,将研究方向向实车应用靠拢以增强与甲方的对接能力,同时呼吁课题组重视技术平台搭建等长期性建设工作。整场研讨在积极而浓厚的学术氛围中顺利结束。
电话:021-69583650 管理员邮箱:2015qgy@tongji.edu.cn
地址:上海市曹安公路4800号同济大学交通运输工程学院A440 邮编:201804
![]() TOPS课题组 页面浏览465,829次/访客70,123人次
TOPS课题组 页面浏览465,829次/访客70,123人次
{kind=link}