本期介绍的研究课题来自于TOPS交通流理论与深度仿真小组,课题名称为《面向自动驾驶测试的复杂交互行为策略仿真研究》,课题来源于国家自然科学基金(52272313):人机混驾环境下车-车交互机制解析、实验与优化;国家自然科学基金杰出青年基金(52125208):交通系统建模与优化;国家自然科学基金(52402374):面向自动驾驶测试的数-模驱动高真实度动态交互交通流仿真。
01 AV测试的社交困局:背景交通流的行为动因建模
随着自动驾驶汽车(Autonomous Vehicle, AV)的规模化部署,AV与人类交通参与者混合运行的人机混驾交通流已成为现实。然而,当前AV在理解和应用人类社交准则方面仍存在显著不足,即社会交互能力有限,严重制约其在实际交通环境中的适应性。虚拟仿真测试是评估AV运行表现的重要手段。为充分评估AV社会交互能力,需要构建一个不仅能生成合理运动轨迹,还能准确刻画人类交通参与者在社交准则引导下的交互行为(即社会交互行为)的交通流仿真模型。
社交准则通常被个体内化为一套稳定的应对机制,这一隐含于行为背后的交互方针可被视作策略,指导其在面对不同情境时如何判断和选择。在具体交互过程中,个体会实时与交互对象进行信息交换,动态形成具象化的策略表现,即合作/竞争倾向,并据此执行具体行为动作(如图1所示)。因此,建模社会交互行为需完整刻画“环境理解-合作/竞争倾向形成-动作执行”的行为链条,本研究将能够描述该过程的建模方法称为策略仿真。
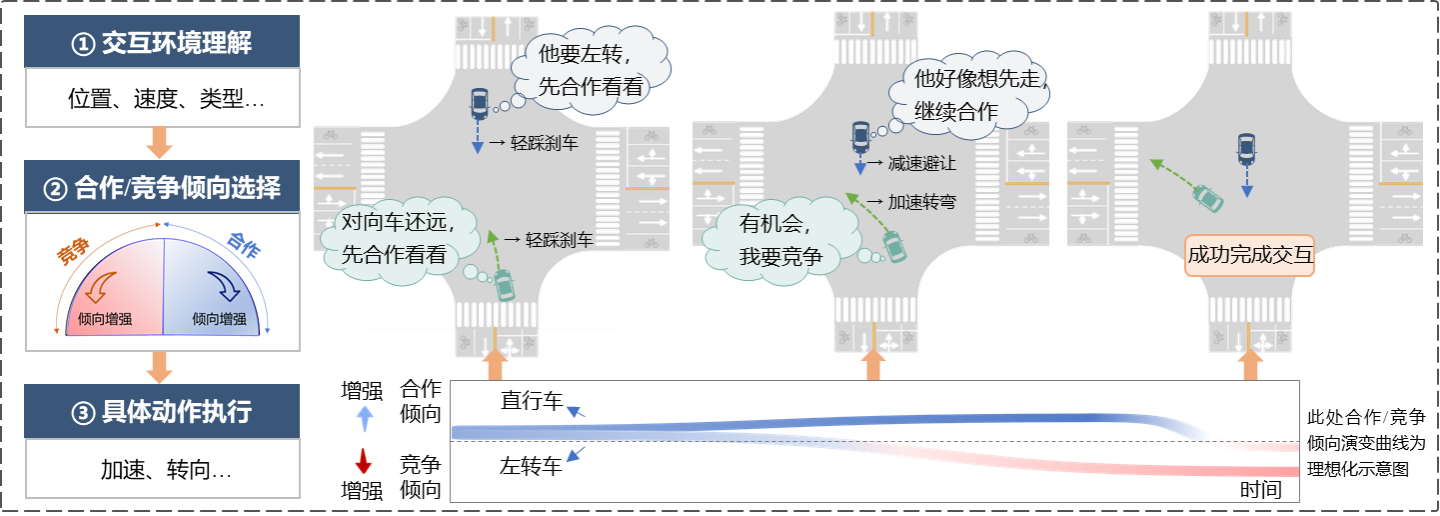
图1 无保护左转车-直行车社会交互行为
本研究聚焦于交叉口、汇入区等强交互场景下的复杂交互行为建模,多方权责边界较为模糊,例如转向与直行、汇入等,旨在为AV提供真实可信的仿真测试环境。然而,实现复杂交互行为策略仿真建模存在以下难点与挑战:
1. 从状态复现到策略建模的深化:传统仿真框架多聚焦于轨迹层面的还原,主要关注个体“做了什么”,对行为“为何如此”的交互机理建模不足。需构建具备学习与解析能力的仿真框架,实现从状态到策略的深化过渡。
2. 合作/竞争倾向与环境之间的耦合机制建模:作为策略在具体情境中的具象化结果表达,倾向具有显著的情境依赖性,体现出动态连续特征。现有研究对其演化过程关注不足,缺乏对该倾向与多主体交互环境之间时空耦合关系的精准刻画。
3. 异质交通参与者差异化交互策略的一体化建模:机动车、非机动车与行人在交互策略上存在本质差异,后两者常形成群体,个体受群体引导且存在行为分化。现有仿真框架难以兼容多类型交通参与者的交互策略,需构建支持差异化策略建模的一体化仿真模型。
针对上述挑战,本研究首先基于多智能体模仿学习构建策略仿真基础框架,为复杂交互行为建模奠定基础;随后,针对机动车流交互场景,在框架基础上构建能够深入刻画多车合作/竞争倾向动态演变的策略仿真模型;进一步拓展至混合交通流,考虑机动车、非机动车与行人的差异化策略,实现多类型交通参与者的一体化建模;最后验证策略仿真对AV社会交互能力测试的有效性,并搭建融入策略仿真的高保真虚拟测试平台。接下来,让我们逐一介绍这四块研究内容的核心方法。
02 从理论到实践:交互行为策略仿真的基础框架构建
围绕“从状态层面的轨迹复现转向策略层面的机制建模”这一核心目标,基于多智能体对抗逆强化学习(Multi-Agent Adversarial Inverse Reinforcement Learning, MA-AIRL)构建了具有可解释性的策略仿真基础框架。本研究以无保护左转相位交叉口处左转与对向直行机动车交互场景作为具体建模场景,开发策略仿真基础框架MAIL-Sim。框架细节如图2所示。
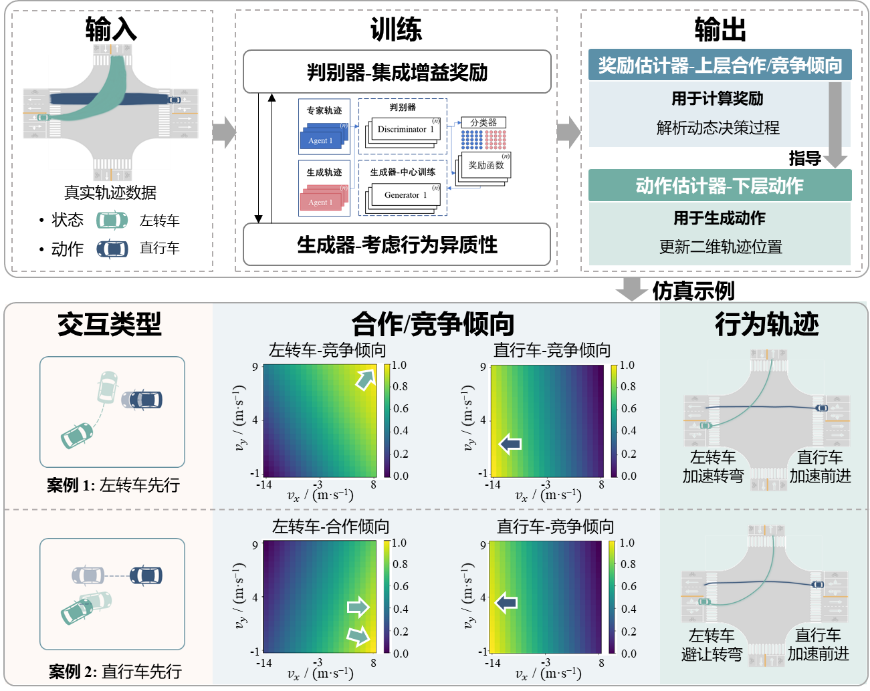
图2 策略仿真MAIL-Sim模型架构
该框架基于真实交互轨迹数据进行训练,能够获得奖励估计器和动作估计器两个关键模块。其中,奖励估计器用于推断动作所对应的奖励,代表交互的内在机制,可解析车辆行进过程中的上层合作/竞争倾向;动作估计器用于生成车辆动作并更新二维轨迹位置,从而实现对合作/竞争倾向及运动状态的精准仿真。
图3展示了MAIL-Sim的模型结构(以左转车辆与对向直行车辆的交互场景为例),由判别器与生成器两大核心模块组成。判别器包含多个二分类函数D(ο, α),用于区分特定的观察值-动作对(ο, α)来自真实轨迹还是生成器,并且为生成器提供奖励函数,可视作上层交互策略的隐式表征。生成器则用于生成动作并更新车辆轨迹,通过学习判别器提供的奖励信号不断优化生成网络。
为充分建模交互策略对动作的指导关系,描述不同行驶方向智能体的行为差异,基于上述结构提出了集成增益奖励的判别器结构以及考虑行为异质的生成器结构,具体如下:
1. 集成增益奖励的判别器:为提升模型对交互策略的解释能力,提高学习效果,在判别器结构中引入增益奖励,与内生奖励共同构成复合奖励结构,用以刻画合作/竞争倾向的动态演变过程,指导生成器生成更符合现实的行为动作。
2. 考虑行为异质性的生成器:为有效建模不同行驶方向车辆的异质行为,在生成器结构中构建异质学习网络。不同行驶方向的车辆在共享基础网络结构的同时,拥有独立的参数集合,从而在兼顾计算效率的同时,更加精确地刻画交通参与者之间的异质交互行为。
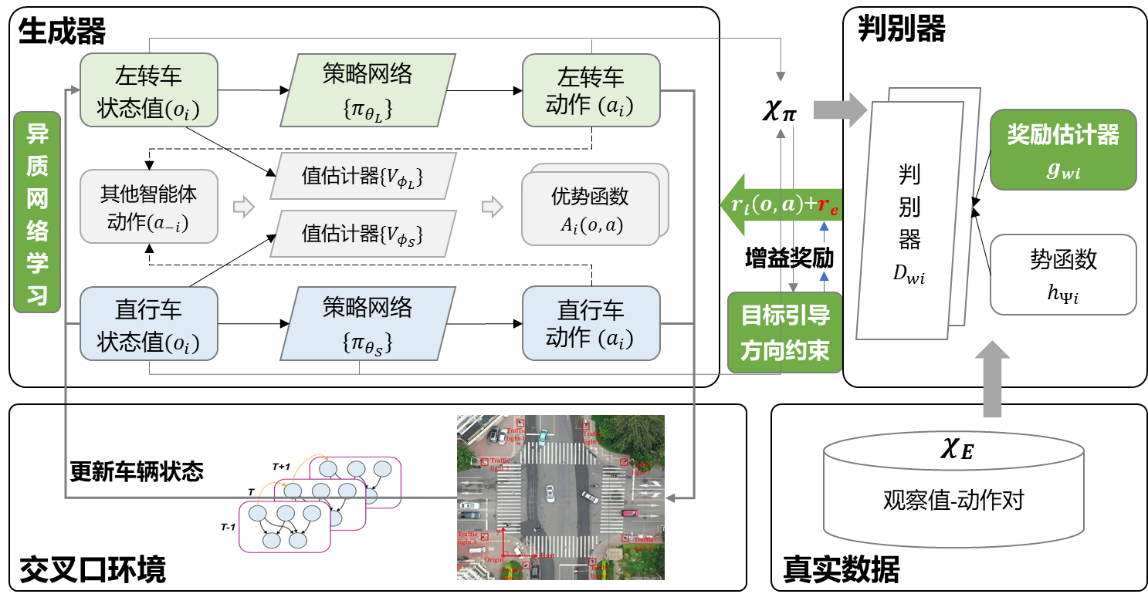
图3 MAIL-Sim结构
选取SinD数据集作为专家数据来源,提取无保护相位下的左转-直行机动车一对一交互事件,用于策略仿真建模。实验结果表明,MAIL-Sim模型有效描述车辆在具体环境下的策略具象化表达,刻画交互过程中合作/竞争倾向的动态演化过程,并准确复现二维轨迹,如表1以及图4所示。
表1 MAIL-Sim模型和基准模型的对比结果
| 评价指标 | MAIL-Sim | H-MA-GAIL | MA-GAIL | MACK | SimNet | LSTM | |
| 位置Avg(ADE) | 3.07m | 3.92m | 4.31m | 4.16m | 3.55m | 4.60m | |
| d |
v | 0.014 | 0.020 | 0.029 | 0.032 | 0.044 | 0.023 |
| θ | 0.006 | 0.017 | 0.023 | 0.032 | 0.017 | 0.068 | |
| 总和 | 0.020 | 0.037 | 0.052 | 0.064 | 0.061 | 0.091 | |
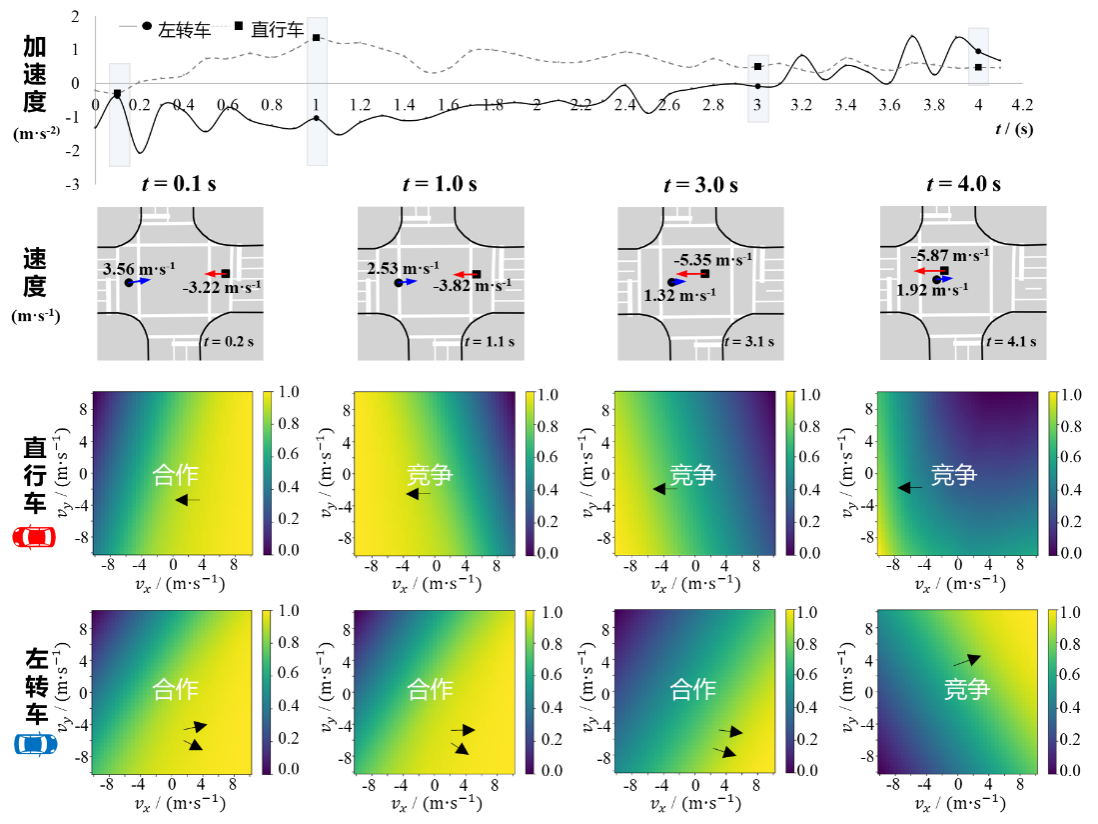
图4 交互场景-合作/竞争倾向解析
03 复杂交互场景解构:多车交互行为策略仿真建模
A. 建模框架
在人机混驾环境中,交叉口、汇入区等多车连续交互场景对AV提出了更加严峻的挑战。为有效评估AV在此类复杂场景中的社会交互能力,亟需构建能够精确刻画多车动态交互过程的策略仿真模型,用以驱动具备社会性交互特征的背景交通流生成。在MAIL-Sim的基础上进一步构建适用于多车交互的社会性策略仿真模型Social-MAIL。模型框架如下图5所示(以交叉口场景为例)。基于真实世界的车辆交互数据训练后,该模型能够输出两个主要模块:奖励估计器和动作估计器。其中,奖励估计器包含了社会价值倾向(SVO)和时空注意力机制。SVO反映了动态连续的合作/竞争倾向,注意力机制则能够解析驾驶员对于交互对象及自身历史状态的关注。与此同时,动作估计器负责生成具体的驾驶动作并更新车辆的二维运动状态,从而实现对复杂交互环境中多车动态倾向及运动状态的同时仿真。
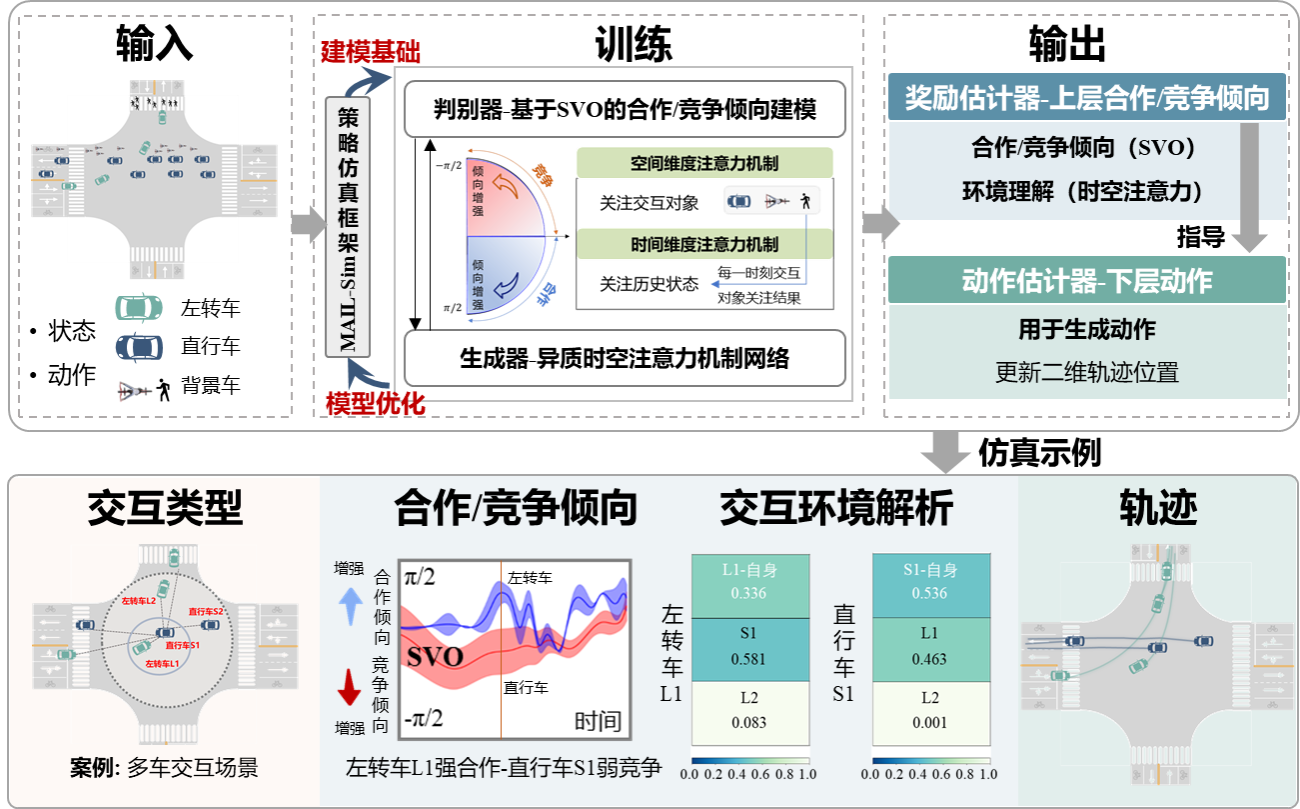
图5 多车策略仿真模型Social-MAIL架构
图6展示了Social-MAIL模型的整体结构(以左转车与对向直行车的交互场景为例),核心模块包括基于SVO的合作/竞争倾向建模以及基于异质时空注意力的交互环境建模。
1. 基于SVO的合作/竞争倾向建模:原始MA-AIRL模型将合作/竞争倾向隐式嵌入基于神经网络的奖励结构中,即使在MAIL-Sim框架中引入增益奖励,在面对多车复杂交互场景时,模型仍难以明确解析车辆在交互过程中的动态连续倾向。心理学与社会学领域相关研究表明,SVO可有效量化人类的倾向选择,衡量个体对自身利益与他人利益之间的关注。因此,本章在判别器的奖励估计模块中引入SVO,显式表征智能体的合作/竞争倾向,学习更具可解释性的奖励函数。
2. 基于异质时空注意力的交互环境建模:为充分建模合作/竞争倾向与环境之间的耦合关系,从交互逻辑的闭环性与信息通路的完整性出发,对MA-AIRL模型中的生成器进行优化。生成器采用多层MLP建模智能体对交互环境的认知,这种方法在处理时序数据方面存在一定局限性,难以充分描述车辆对周围交互对象及自身历史状态的理解,而这些信息对当前决策至关重要。为解决这一问题,本章基于自注意力机制[201]建立时间-空间注意力机制模块,以充分挖掘交互环境在时空维度的特征信息。此外,考虑到不同行驶方向的车辆在行为模式上的差异,沿用MAIL-Sim框架中异质网络的思想,针对不同行驶方向的车辆分别构建专用网络,最终形成异质时空注意力策略网络(H-TSA)。
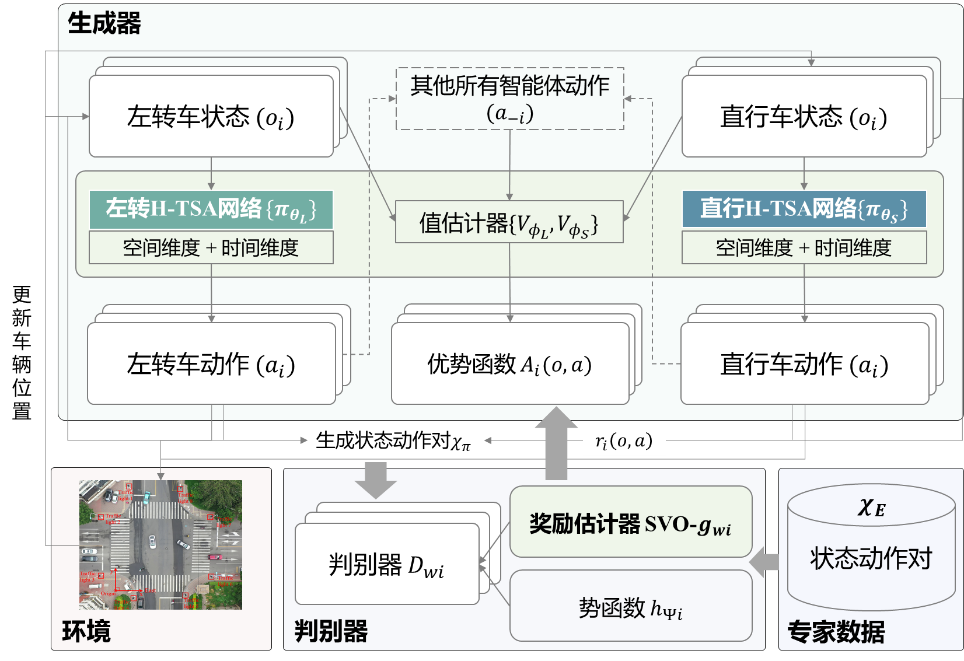
图6 Social-MAIL模型结构
C. 建模实例
选取SinD数据集作为专家数据来源,提取无保护相位下的左转-直行机动车多对多交互事件,用于策略仿真建模。实验结果表明,Social-MAIL模型通过逆向强化学习恢复的基于SVO的奖励函数能够有效捕捉交互机制,成功实现了对合作/竞争倾向动态演变过程的精细化建模;并且,模型生成的场景在微观轨迹位置以及宏观关键交通流参数方面均有较高精度。如表2以及图7-8所示。
表2 Social-MAIL模型和基准模型的对比结果
| 评价指标 | Social-MAIL | H-TSA-MA-GAIL | MA-GAIL | MACK | Social-LSTM | IDM | |
| 位置Avg(ADE) | 3.15m | 3.25m | 3.59m | 3.94m | 4.16m | 5.76m | |
| d |
v | 0.008 | 0.023 | 0.152 | 0.194 | 0.160 | 0.865 |
| θ | 0.005 | 0.008 | 0.029 | 0.048 | 0.260 | 0.006 | |
| Avg(GT) | 0.185 | 0.250 | 0.168 | 0.023 | 0.372 | 0.504 | |
| 总和 | 0.198 | 0.281 | 0.349 | 0.265 | 0.792 | 1.375 | |
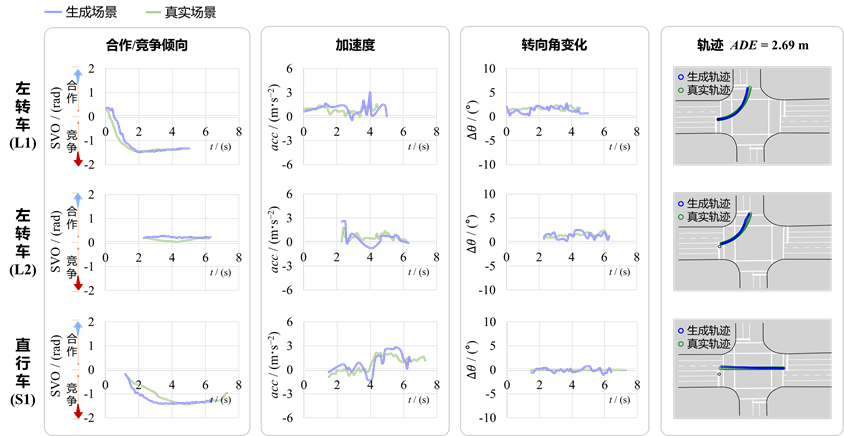
图7 交叉口场景-生成轨迹与真实轨迹动态交互指标对比
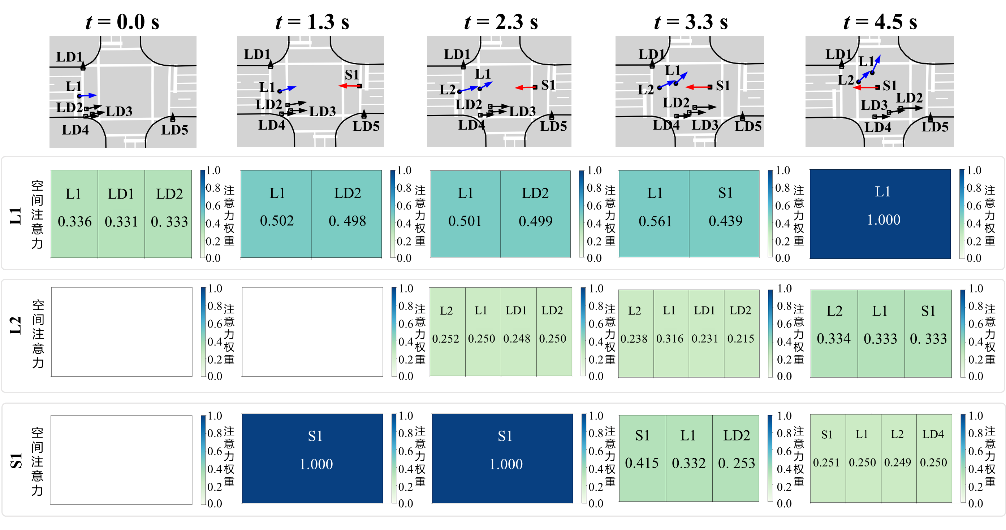
图8 交叉口场景-生成场景动态交互注意力描述
04 混行交通的密码:异质交通参与者交互行为策略仿真建模
在实际道路环境中部署AV时,除了需要考虑与人类驾驶机动车之间的交互外,还需要重点关注非机动车和行人对其的影响。机动车、非机动车和行人混行环境广泛存在于城市道路交通系统中。后两者作为道路的重要参与者,其行为具有高度的随机性和不确定性,且缺乏严格的车道规则约束,容易形成从众群体。这种复杂的交互环境对AV的社会交互能力提出了更高的要求。因此,构建能够同时真实模拟机动车、非机动车和行人社会交互行为的一体化策略仿真模型具有重要意义。本研究在Social-MAIL的基础上,构建了适用于混合交通流交互行为建模的策略仿真模型,称为MTSIM(Mixed Traffic Simulation)模型。选择无保护左转相位交叉口处左转机动车与对向直行机动车、非机动车、行人交互场景作为具体建模场景,具体框架如下图9所示。
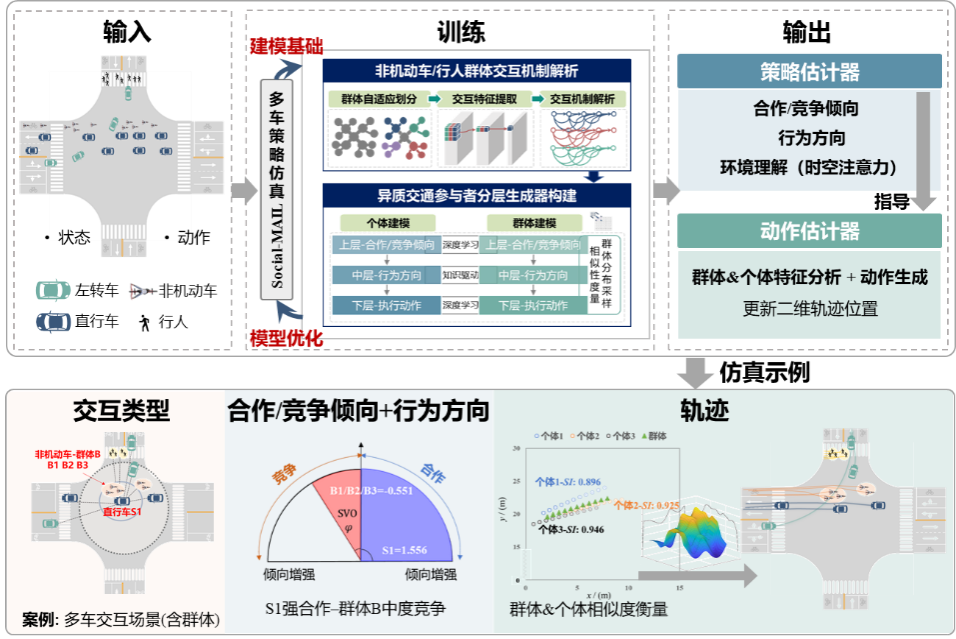
图9 混合流策略仿真模型MTSIM架构
图10展示了MTSIM模型的整体结构(以左转车与对向直行车的交互场景为例)。为增强合作/竞争倾向对生成行为的直接指导能力,本研究进一步在生成器模块中显式构建“环境理解-倾向形成-动作执行”的闭环交互过程,以实现更加精准的社会交互行为建模。核心模块包括面向机动车的分层生成器构建以及考虑群体行为的非机动车/行人分层生成器构建。
1. 面向机动车的分层生成器构建:在交互环境中,个体基于对周围环境的理解,动态调整其合作或竞争倾向,并基于这一倾向明确具体的行为方向(如加速/减速、转向/绕行等),最终执行相应的动作。基于这一交互逻辑,本章采用“合作/竞争倾向-行为方向-动作执行”的层次化结构,针对机动车的生成器构建分层策略网络。简言之,该框架分为三层:上层基于Transformer架构,整合时空交互信息生成合作/竞争倾向。中层结合倾向和知识驱动方法确定具体交互行为方向,作为上层与下层的关键连接,以确保倾向与动作在社会交互框架下的一致性。下层则基于上层与中层的指导学习具体动作。考虑到左转机动车与直行机动车的行为模式差异,沿用MAIL-Sim框架中的异质建模思想,分别为两类交通参与者构建专用生成器网络,以提升建模的针对性与精度。
2. 考虑群体行为的非机动车/行人分层生成器构建:非机动车与行人的生成器策略网络结构沿用机动车的分层架构,但在交互逻辑上有所差异:机动车主要基于个体策略进行交互,而非机动车与行人则受到群体的影响。对于存在群体的情况,群体内个体将在群体合作/竞争倾向的引导下,根据自身行为与群体平均行为的相似度确定具体动作。最终动作由中层网络的方向约束模块进行调节,以确保个体行为在群体一致性与个体差异性之间取得平衡。考虑到非机动车与行人在行为特征和运动模式上亦存在差异,分别为其构建专用生成器网络。
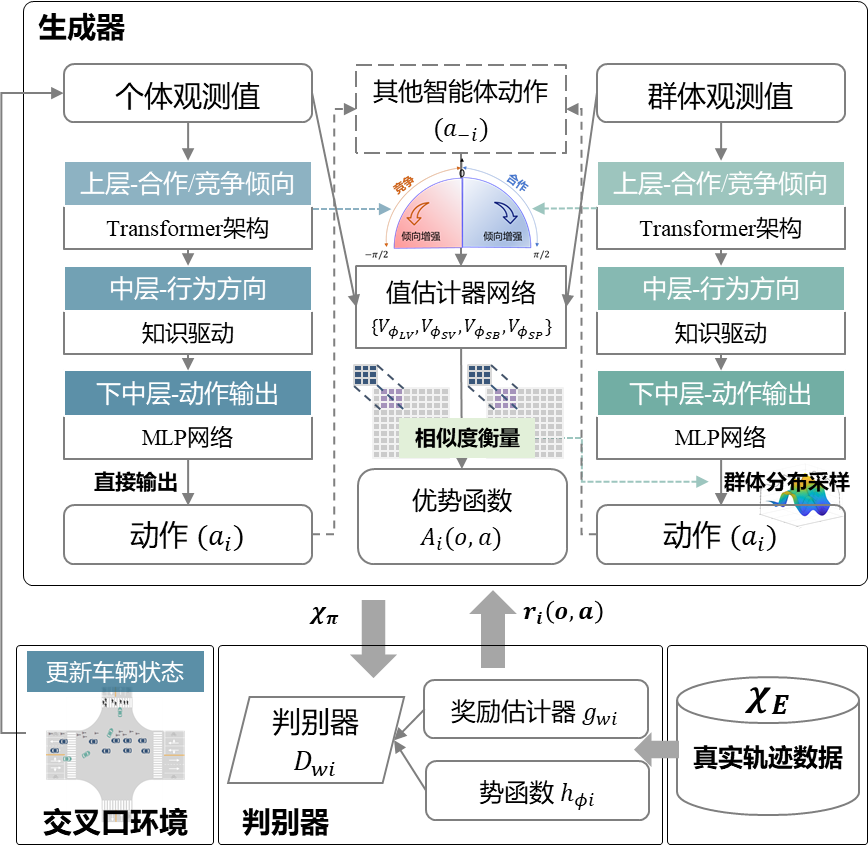
图10 MTSIM模型结构
C. 建模实例
选取XXJH数据集作为专家数据来源,提取无保护左转相位交叉口处,左转机动车与对向直行机动车、非机动车、行人的交互场景作为具体建模场景。实验结果表明,分层策略网络的构建使得模型能够充分捕捉不同交通参与者的合作/竞争倾向,并准确刻画非机动车以及行人的群体决策过程。此外,模型在微观层面能够生成符合真实交互特征的轨迹位置,在宏观层面可准确复现关键交通流参数。如表3以及图11-12所示。
表3 MTSIM模型和基准模型的对比结果
| 评价指标 | MTSIM | Social-MAIL | MTSIM-GAIL | MA-GAIL | MACK | Social-LSTM | IDM | |
| 位置Avg(ADE) | 3.59m | 4.02m | 4.00m | 4.67m | 5.07m | 5.99m | 9.84m | |
| d |
v | 0.100 | 0.072 | 0.073 | 0.132 | 0.089 | 0.116 | 0.154 |
| θ | 0.010 | 0.017 | 0.016 | 0.009 | 0.020 | 0.053 | 0.010 | |
| Avg(GT) | 0.026 | 0.036 | 0.017 | 0.065 | 0.023 | 0.026 | 0.014 | |
| 总和 | 0.136 | 0.125 | 0.106 | 0.206 | 0.132 | 0.195 | 0.178 | |
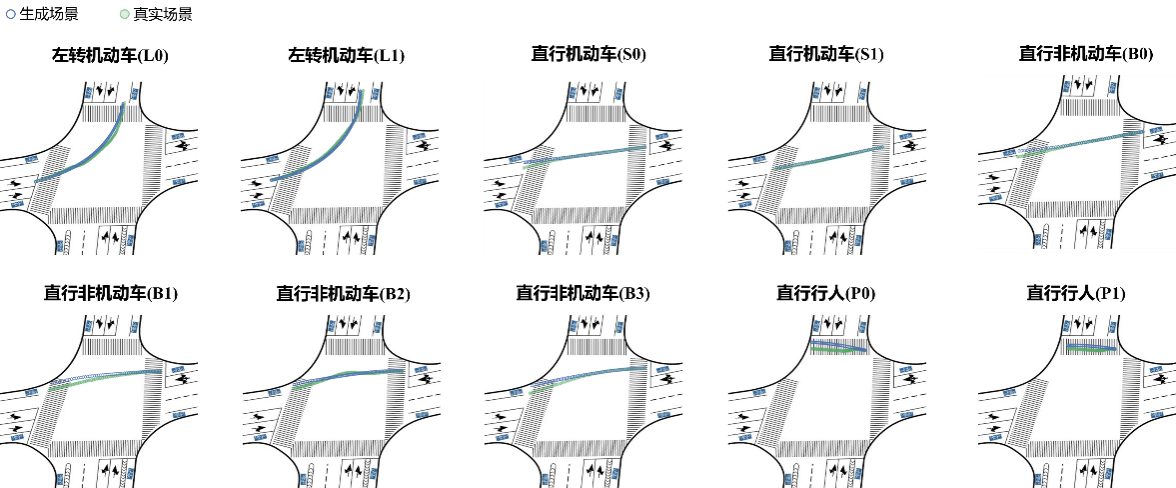
图11 混合交通流典型交互场景轨迹对比
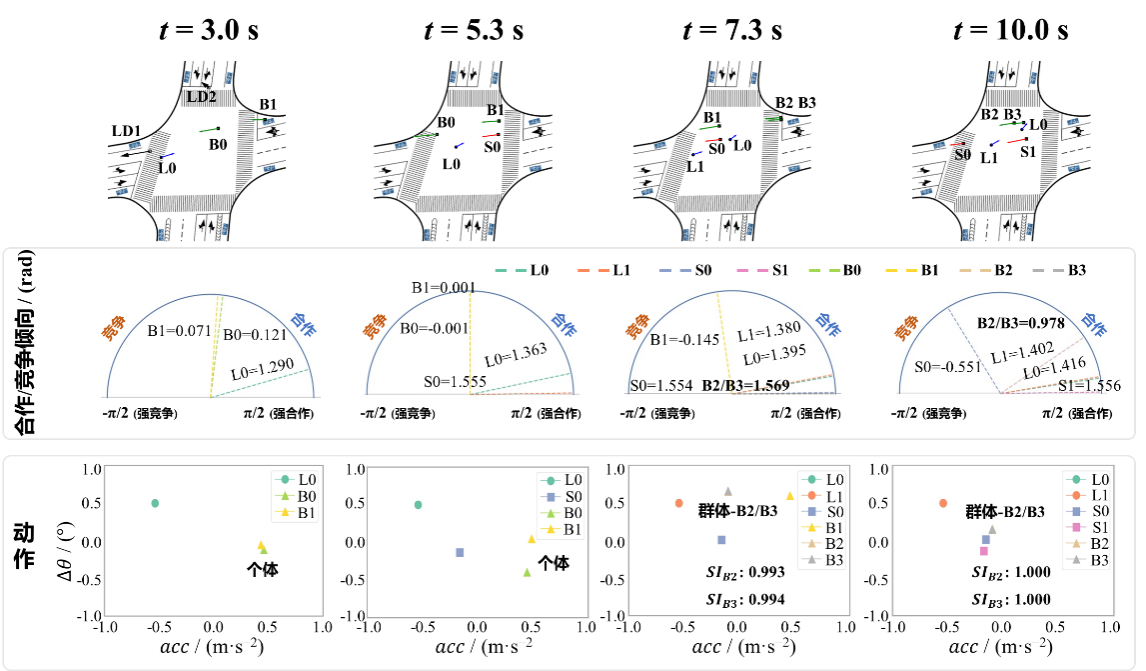
图12 典型场景机动车-非机动车合作/竞争倾向解析
05 以虚验实:面向AV测试的策略仿真有效性验证
评判仿真模型能否有效支撑AV社会交互能力的测试,应从两个核心维度进行考察:
其一,多样化交互场景的构建能力。在实际道路环境中,AV所面对的交互情境高度复杂且多样。例如,交通参与者的合作/竞争倾向(具体情境中策略的具象化体现)可能随着交互进程逐步演化,呈现出渐进式的行为模式;也可能发生突变,如由合作突然转向高强度竞争,显著提升交互的不确定性。因此,有效的仿真模型应具备生成多样化测试场景的能力,覆盖不同的交互策略组合,支持AV在不同情境下社会交互能力的测试。
其二,测试结果的量化能力。多样化交互场景的构建是开展测试的前提,但仿真模型测试有效性还依赖于其对AV行为表现的量化与分析能力。因此,有效的仿真模型应能够获取交互各方的实时合作/竞争倾向,客观量化AV的社会交互能力,为算法优化提供可靠依据。
基于上述目标,本研究设计并开展了测试实验,实验在策略仿真模型所构建的虚拟环境中进行。具体而言,基于MTSIM模型构建了两类关键测试场景:一是交互策略自然演化场景,模拟背景车在遵循社交准则下的合作/竞争倾向动态演化过程,旨在还原人类交互行为的自然特征,测试AV在常见社会交互场景中的适应能力;二是交互策略定向调控场景,通过人为干预背景车在具体情景下的策略表现以引入突发性扰动,模拟高风险或非预期交互情境,以评估AV在高变动条件下的策略识别与应变能力。上述两类场景兼具行为普遍性与挑战复杂度,为全面评估AV在复杂交互环境中的行为能力提供多维场景支持,如图13所示。进一步,提出交互一致性指标作为社会交互能力的定量评价依据,并在上述测试场景中对AV行为进行系统评估,从而验证MTSIM模型在支持社会交互能力测试任务中的有效性。
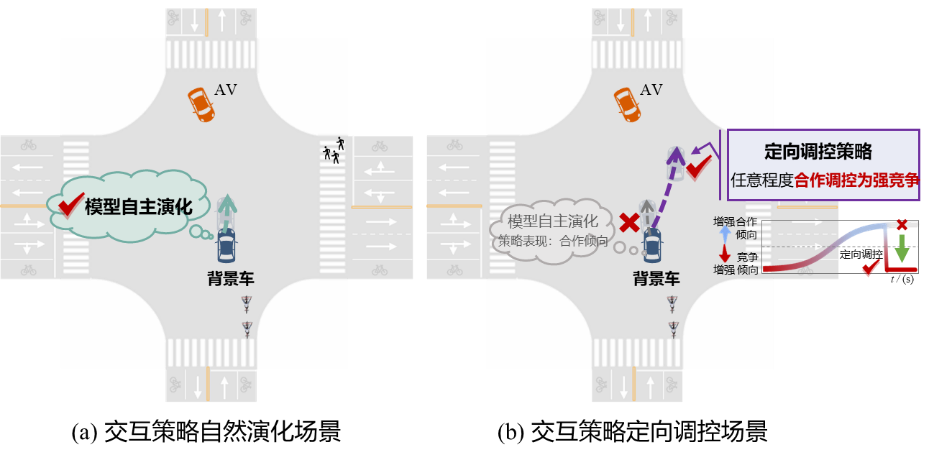
图13 社会交互测试场景示意
测试实验在MTSIM模型所构建的虚拟环境中进行,所选自动驾驶规划算法为Lattice规划器,该算法源自DARPA无人驾驶挑战赛。从XXJH数据集中筛选出100个涵盖多类型交通参与者的强交互场景,以场景的初始状态作为测试场景的初始状态,包括交通参与者类型、数量以及进入场景的时间等关键参数。在每个场景中均选定一辆左转机动车作为AV,将其初始状态输入至Lattice规划器,由其控制后续行为;其余则由MTSIM模型控制作为背景车。测试结果如表4及图14所示,其中背景车简称为BV(代表机动车、非机动车及行人)。
表4 AV测试结果
| 交互策略自然演化场景 | 交互策略定向调控场景 | 整体社会交互能力等级 | |||
| 交互一致比例 | 65% | 交互一致比例 | 41% | 3 中等等级 |
|
| AV合作-BV竞争比例 | 51% | BV策略突变前 | AV合作-BV合作比例 | 73% | |
| AV竞争-BV合作比例 | 14% | BV策略突变后 |
AV竞争-BV竞争比例 | 16% | |
| AV合作-BV合作比例 | 35% | AV合作-BV竞争比例 | 11% | ||
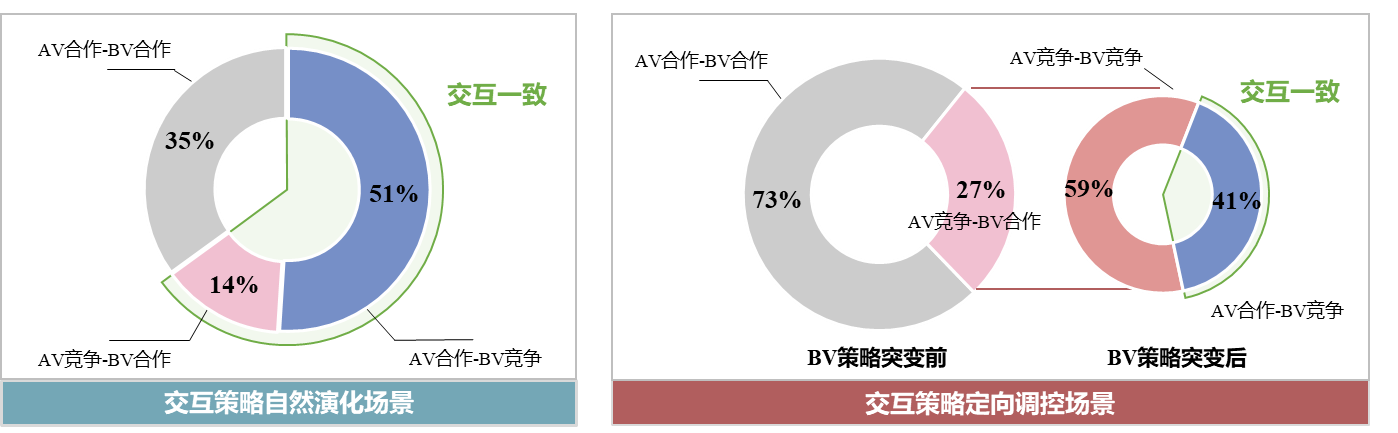
图14 AV测试结果可视化
上述评估结果表明,MTSIM模型具备生成多样化测试场景的能力,能够覆盖不同的交互策略组合。基于交互一致比例指标,模型可实现对AV规划算法在交互任务中的社会交互能力进行定量评估,从而有效反映其社会交互水平。在交互策略定向调控场景中,本研究重点验证了由合作倾向突变为高度竞争的关键情境,所提出的场景构建方法为其他策略变换模式下的场景构建提供了方法论支撑。
为推动策略仿真的实际应用,本研究依托上海AI实验室研发的LimSim(Long-term Interactive Multi-scenario traffic Simulator)交通仿真器,构建了集成策略仿真能力的自动驾驶虚拟测试平台。该平台可动态生成多种交互策略模式下的背景交通流,支持与AV的实时双向交互,同时具备高保真的交通场景渲染能力,能够可视化测试交互过程,为AV社会交互能力的评估提供可靠的仿真测试环境。
为验证LimSim平台的实际应用效果,将Lattice规划器集成至平台以控制AV,并开展相关测试。基于SUMO绘制了一个交叉口场景,用于评估AV在执行无保护左转任务中的社会交互能力表现。采用SUMO仿真工具随机生成100组包含机动车、非机动车与行人的对向直行交通参与者初始状态,分别构建交互策略自然演化场景与策略定向调控场景。图15展示了仿真测试界面。其中,左上角为路网全局视图,左下角实时显示仿真参数(包括仿真步长与车道信息),右侧则聚焦于交互细节,实现对AV行为的动态可视化监测。
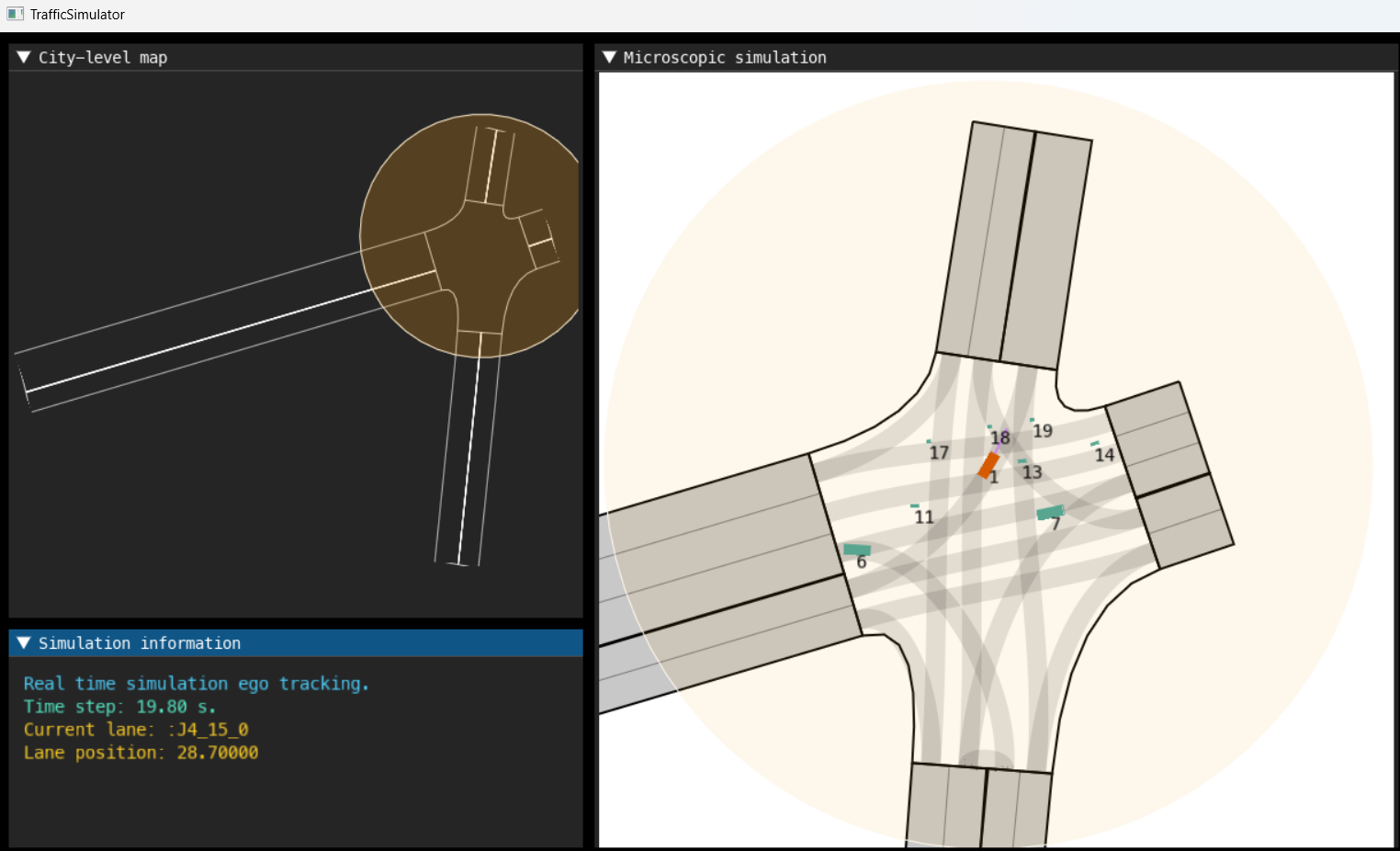
图15 实时仿真可视化效果
基于交互一致比例指标,对Lattice规划器控制的AV在MTSIM驱动的背景交通流环境中的社会交互能力进行了定量评价,具体评估结果见表5及图16。
表5 基于虚拟仿真测试平台的AV测试结果
| 交互策略自然演化场景 | 交互策略定向调控场景 | 整体社会交互能力等级 | |||
| 交互一致比例 | 56% | 交互一致比例 | 27% | 2 较低等级 |
|
| AV合作-BV竞争比例 | 41% | BV策略突变前 | AV合作-BV合作比例 | 63% | |
| AV竞争-BV合作比例 | 15% | BV策略突变后 |
AV竞争-BV竞争比例 | 27% | |
| AV合作-BV合作比例 | 44% | AV合作-BV竞争比例 | 10% | ||
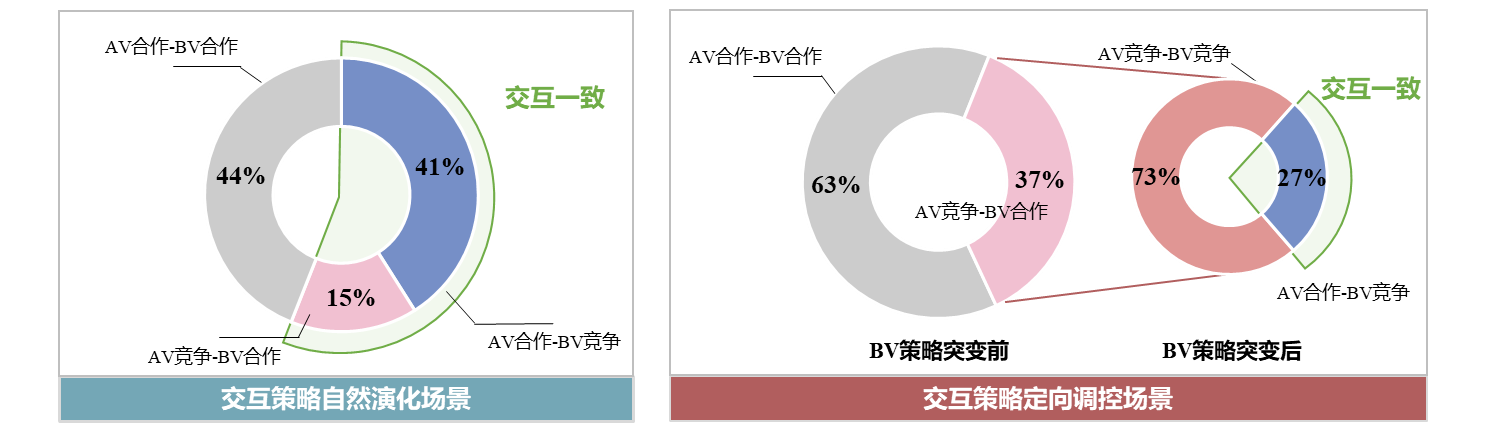
图16 基于虚拟仿真测试平台的AV测试结果可视化
结果表明,基于LimSim仿真器构建的融合策略仿真的虚拟测试平台,能够生成具有多样交互策略的测试场景,为自动驾驶系统提供一个可重复、可扩展的测试环境。结合交互一致比例指标,该平台可量化AV在不同测试场景下的社会交互能力,有效评估其对人类在具体场景中策略表现的识别与响应能力。
本研究虽然取得了一些研究成果,但在面向AV社会交互能力测试的策略仿真建模方面,仍存在需进一步深入探索的研究工作,总结如下:
1. 考虑人机混驾交互模式变化,刻画AV对人类交互策略的影响:首先,策略仿真建模中仍需进一步考虑AV对人类交通参与者交互策略的影响。本研究所构建的策略仿真模型主要基于对人类社会交互行为的学习,用于生成具有社会交互特性的背景交通流,以构建更加真实的测试环境。然而,当AV进入实际交通环境后,人类在与其交互时所采用的策略可能显著区别于与其他人类驾驶者交互时的策略。未来研究应进一步精细化人类交通参与者的策略建模过程,重点刻画其在面对AV时合作/竞争倾向的动态调整机制。
2. 打通场景边界,实现策略仿真在多类型场景中的连续建模:其次,策略仿真模型在多类型场景的连续仿真方面可以进一步优化。本研究所提出的策略仿真模型已在多个典型强交互场景(如交叉口、汇入区等)中完成建模,具备良好的适应能力。但当前模型仍需针对不同场景独立训练,在多场景动态切换的连续测试方面存在局限。现实驾驶过程通常涉及高速公路、复杂路口、住宅区等多种交通环境的连续过渡,若每类场景均需独立建模,将导致测试流程繁复、效率降低。因此,未来研究可聚焦于构建统一的策略仿真框架,打通场景边界,实现不同交互场景的连续建模与无缝衔接,进一步支撑AV在复杂交通环境中的测试。
3. 探索模型自进化,提升策略仿真模型在未知场景下的泛化能力:最后,策略仿真模型在未知场景泛化能力方面仍有进一步提升空间。本研究所提出的策略仿真模型在具有专家示范数据的典型交互场景中均展现出良好的建模能力,能够生成多样化的社会交互行为,有效支撑自动驾驶系统的社会交互能力测试。然而,现实交通系统中场景数量庞大、类型繁多,许多关键交互场景难以获取专家行为数据,基于专家示范的策略学习方式在应对未见场景时存在一定局限性。未来研究可基于大语言模型、知识蒸馏等方法进一步推动策略仿真从“专家引导”向“模型自进化”演进,提升模型在缺乏先验数据条件下的适应性与扩展性,增强其在复杂未知环境中的策略生成能力。
关于研究方法和实验设计的详细内容,可参考论文原文:
[1] Wang S, Ni Y, Miao C, Sun J, Sun J. A multi-agent social interaction model for autonomous vehicle testing[J]. Communications in Transportation Research, 2025.
[2] Wang S, Ni Y, Sun J, Sun J, Xiao L. Modelling the social interactions at mixed-flow intersection with multi-agent imitation learning[C]// Proceedings of the 104th Transportation Research Board Annual Meeting, Washington D.C., USA, 2025.
[3] 倪颖, 王诗菡, 孙剑, 孙杰, 李建强. 基于多智能体模仿学习的交叉口复杂交互行为建模仿真[J]. 同济大学学报, 2024.
电话:021-69583650 管理员邮箱:2015qgy@tongji.edu.cn
地址:上海市曹安公路4800号同济大学交通运输工程学院A440 邮编:201804
![]() TOPS课题组 页面浏览465,829次/访客70,123人次
TOPS课题组 页面浏览465,829次/访客70,123人次
{kind=link}