01 自动驾驶的"成长烦恼":为何数据驱动的模型难以持续进化?
如果把自动驾驶系统比作一个正在学车的AI司机,它的成长轨迹与人类惊人相似:需要通过大量"驾驶经验"积累知识(数据训练),在教练指导下形成条件反射(监督学习),再通过实际路况磨炼技巧(强化学习)。但现实中的AI司机却面临着比人类更棘手的"发育问题",这些问题的根源可以用一个公式概括:
系统智能 = 数据质量 × 算法效率 × 进化能力
而这个公式的背后,对应的正是自动驾驶决策系统面临的三大“成长瓶颈”。
第一重困境:数据“营养”不均衡
数据驱动模型遵循"吃什么饭长什么肉"的基本法则,自动驾驶需要海量高质量驾驶数据"喂养",但现实数据采集就像在沙漠中寻找绿洲——成本高昂且分布不均。极端场景(如紧急避让)的数据更是如同稀有矿产,难以通过常规路测获取。
第二重挑战:多任务学习的“偏科”现象
现有的强化学习模型就像只会单项运动的运动员,在直道行驶表现出色,但遇到十字路口、环岛等多任务复合场景时,往往顾此失彼。更棘手的是,多任务学习时不同任务目标会产生"梯度战争",导致模型性能不升反降。
第三座大山:持续学习的“记忆诅咒”
当模型学习新场景时,就像在沙滩上写字——新知识会覆盖旧记忆。这种"灾难性遗忘"现象使得系统难以实现真正的持续进化,每次更新都像从头开始学走路。
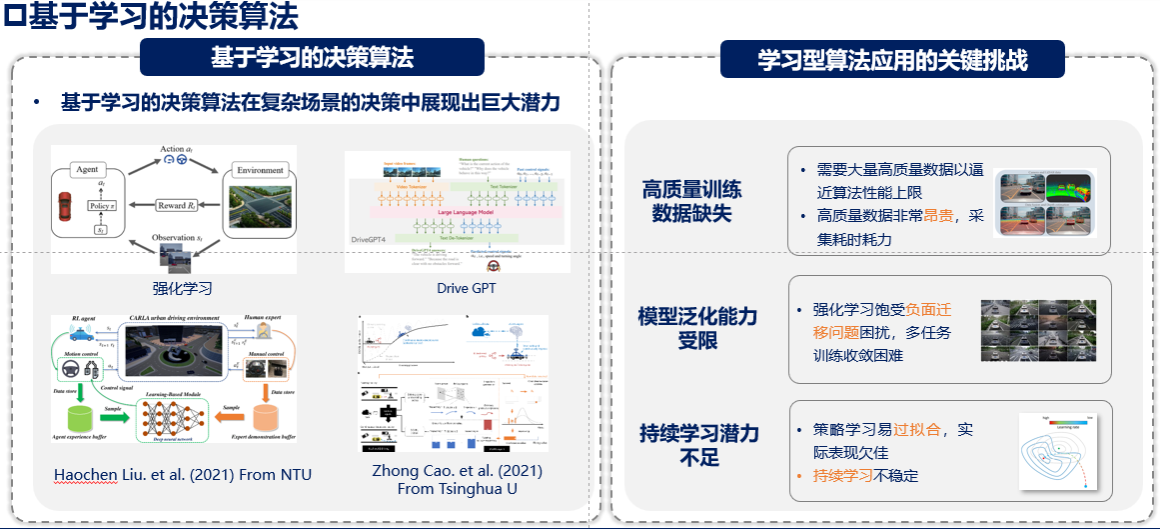
图1 基于学习的决策算法:发展与挑战
破局之道:Transformer构建的“可进化决策大脑”
我们的解决方案灵感源自人类大脑的学习机制——先建立知识框架(离线预训练),再通过实践不断优化(在线微调)。具体构建了三层进化体系:
(1) 专家智库建设(基于强化学习专家采样的教师策略建模):训练多个"专项教练"(RL专家模型),分别精通十字路口、匝道汇入等特定场景;
(2) 知识体系构建(基于自回归序列建模的决策GPT模型离线预训练):基于Transformer架构建立决策GPT模型,通过离线预训练整合专家经验;
(3) 终身学习机制(基于熵正则和策略微调的GPT模型持续进化):提出熵正则化微调技术,让模型像人类司机一样在持续实践中优化决策。
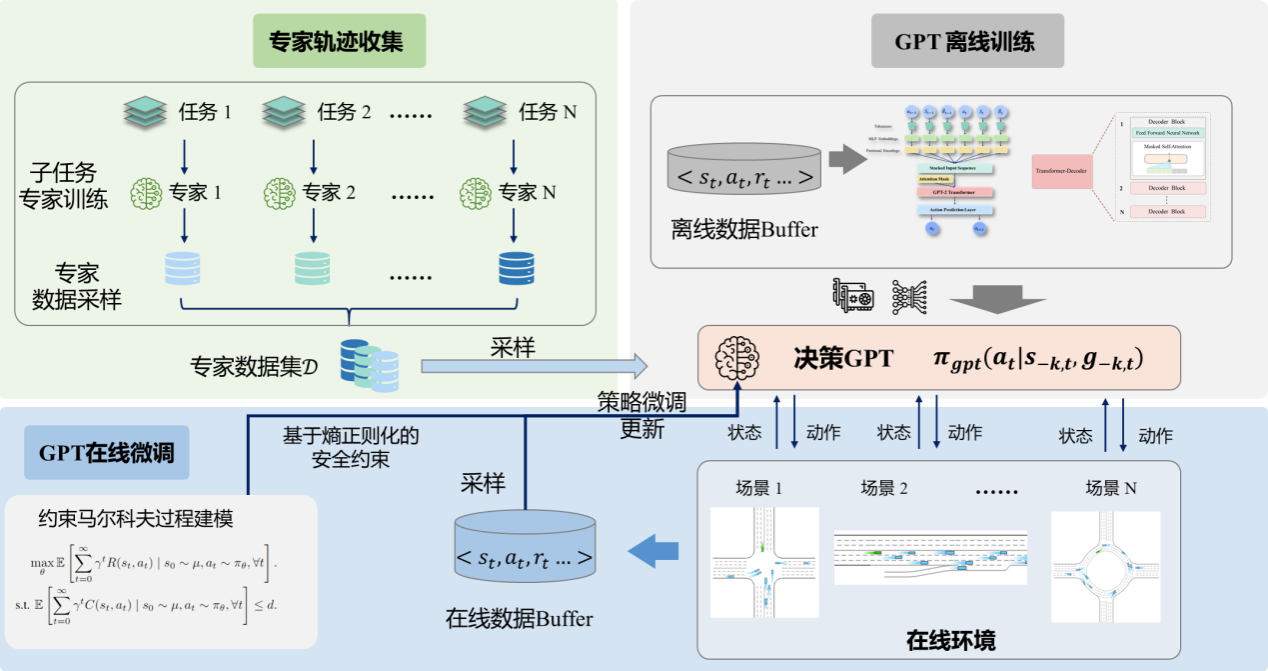
图2 基于决策Transformer的持续学习模型训练流程
02 数据是一切的基础:基于强化学习专家采样的教师策略建模
自动驾驶决策智能体的性能很大程度上取决于其训练策略的质量,而策略质量的核心在于训练数据的多样性与高质量度。在现实世界中,直接收集多类场景的专家驾驶数据不仅成本高昂,更涉及诸多安全风险。为解决这一困境,我们提出了一种创新的数据获取方法。
我们的方法核心是"先分后合":
首先在多个决策子任务上分别训练强化学习专家模型(Expert Policies);
然后利用这些专家策略作为教师(Teacher Policies)收集高质量演示数据;
最终构建一个多任务离线数据集,为决策GPT模型预训练提供坚实基础。
这种方法解决了一个现实难题:在复杂多变的交通场景中,训练单个全能型强化学习决策智能体极具挑战性。通过将问题分解,我们能够在单个决策任务上训练专精的RL专家智能体,这些"小而专"的模型在特定任务上表现出色。
 图3 基于强化学习专家采样的离线数据集收集流程
图3 基于强化学习专家采样的离线数据集收集流程
我们选择近端策略优化(Proximal Policy Optimization, PPO)作为基础强化学习算法。相比传统的策略梯度方法(如REINFORCE)或基于值函数的方法(如DQN),PPO通过巧妙约束策略更新幅度,大幅提高了学习的稳定性和样本利用效率,使其成为训练专家策略的理想选择。
(1) 注意力增强的策略网络
策略网络是智能体决策的核心。为提升其在复杂自动驾驶环境下的鲁棒性和泛化能力,我们将注意力机制融入策略网络设计中。注意力机制能够:
自动聚焦于输入数据中的关键部分
智能加权不同输入特征的重要性
高效捕捉长期依赖关系和动态环境变化
我们设计了一个基于注意力机制的编码器-解码器结构,包含三个关键模块:
编码器(Encoder):将输入的状态和观察信息转化为高维特征表示;
自注意力层(Attention Layer):通过多头自注意力机制对输入特征进行加权处理,使网络能够关注不同时间步的关键信息;
解码器(Decoder):将自注意力层的输出映射到动作空间,生成基于当前状态和历史信息的动作概率分布。
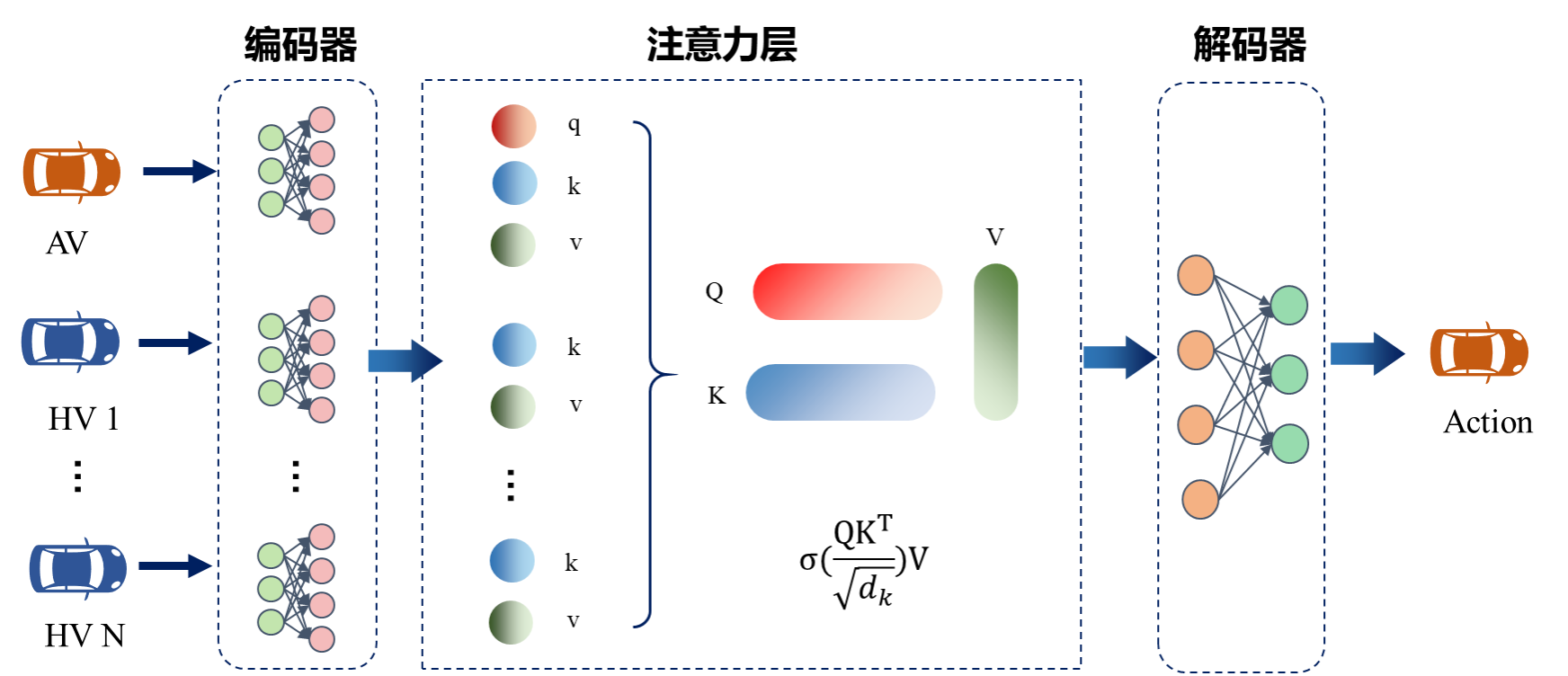
图4 基于注意力机制的策略网络示意图
完成子任务专家策略训练后,我们设置了五类基元场景作为数据采集环境:
城市道路
T型交叉口
十字型交叉口
匝道汇入
环岛
在这些场景中,我们系统性地列出所有驾驶任务,加载专家模型进行数据采集,最终构建了一个丰富多样的离线专家数据集,为后续的预训练奠定了坚实基础。
03 夯实基础是关键:基于自回归序列建模的决策GPT模型离线预训练
想象一下,如果让ChatGPT来驾驶汽车,会发生什么?传统强化学习在处理多任务决策时往往力不从心,就像一个只会做一道菜的厨师面对不同菜系的挑战。而Transformer网络在自然语言处理领域的"全能选手"表现,让我们产生了一个大胆想法:为什么不让自动驾驶决策也"说人话"呢?
GPT(Generative Pre-trained Transformer)模型家族由OpenAI打造,就像是一个不断进化的AI物种,其"基因密码"包含三个关键要素:
单向思考机制:采用Decoder-Only结构,通过掩码注意力实现从左到右的单向信息流,就像人类阅读文本一样循序渐进。
海量无监督学习:在没有明确标签的情况下,通过自我预测下一个词的游戏来理解世界。
灵活的任务适配:通过提示微调(Prompt Tuning)快速适应各种下游任务,宛如一个通晓百科的专家。
从GPT-1到GPT-3,模型参数从1.17亿暴增至1750亿,计算规模呈指数级增长。为了驾驭这头"数字巨兽",研究人员引入了稀疏注意力机制和混合精度训练等技术,就像给超级计算机装上了更高效的"引擎"。
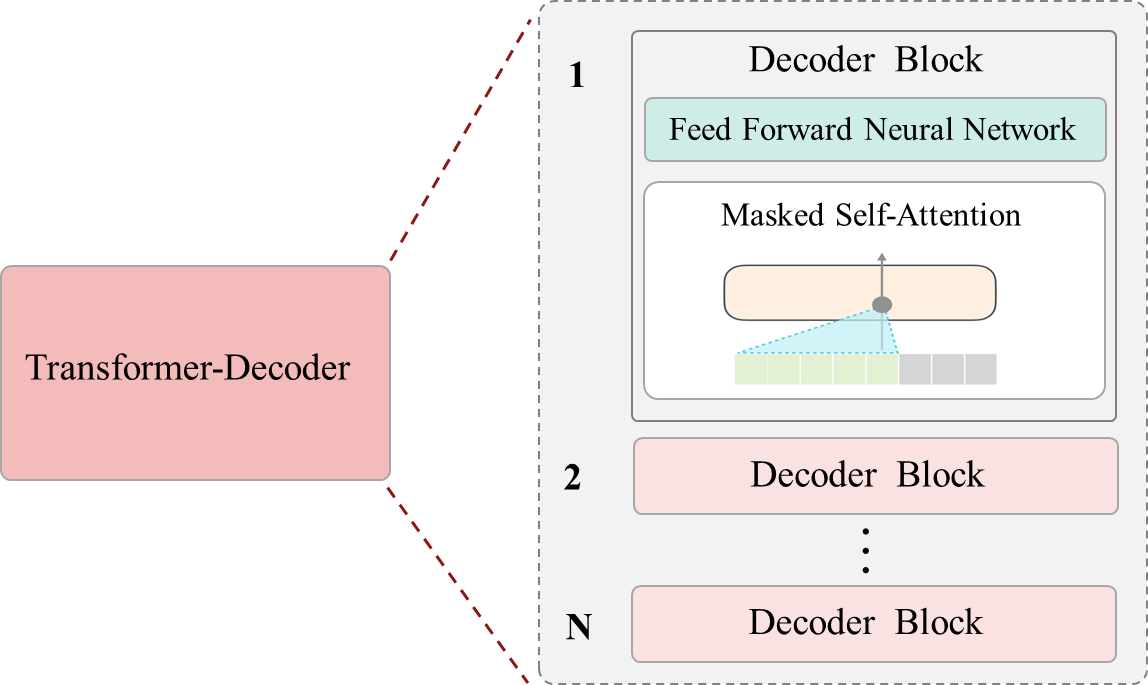
图5 GPT网络架构图
自动驾驶决策的原始数据来自专家策略采集的离线轨迹,形式上表现为一系列时间步的元组序列:

要让这些结构化数据适配GPT的胃口,我们需要一位"翻译官"。通过目标导向的奖励重参数化,我们将任意时刻t的奖励信号重构为从当前至终点的累积奖励:
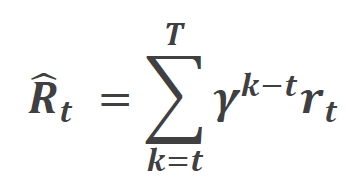
其中γ∈[0,1]是折扣因子(类似于经济学中的"现值系数"),T是轨迹总时长。这一操作相当于让模型具备"远见卓识",不仅关注眼前利益,还考虑长远回报。处理后的轨迹序列变为:
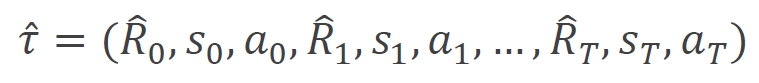
我们的驾驶决策GPT模型采用Decoder-Only结构,就像一座三层宝塔,层层递

在自动驾驶的实时应用中,决策延迟即安全隐患。为满足毫秒级响应需求,我们设计了基于键值缓存的增量解码机制——在线推理时,模型仅对最新观测进行注意力计算,历史信息通过缓存复用,显著降低计算复杂度。这种自回归建模通过滑动窗口缓存与安全约束解码的协同设计,实现了高效、安全的实时决策,就像人类驾驶员在保持对道路历史记忆的同时,快速应对新出现的交通状况。
通过上述设计,我们的决策GPT模型不仅继承了Transformer在自然语言处理领域的强大表达能力,还针对自动驾驶决策的特殊需求进行了深度定制,为机器"驾驶员"提供了一套更加智能、灵活的"思考框架"。
图6 决策GPT框架图
在本研究中,我们首先在 交叉口左转、直行、右转 三个典型任务上对模型进行了小规模测试,以评估不同参数规模的 GPT 决策模型(MTD-GPT) 在自动驾驶场景中的表现。我们通过调整 解码器层数 和 嵌入维度,训练了参数规模不同的多个模型(约 600K、1.2M、2.4M、38M、75M),并从多个角度进行比较分析。
在训练过程中,我们主要观察了 训练损失、动作错误率、测试任务成功率 三个指标的变化趋势(图 7)。实验结果表明:
随着模型参数数量的增加,训练收敛速度明显加快。相比于小参数模型,较大模型可以更快地适应离线数据,表现出更优的学习能力。
参数规模为38M和75M的模型在训练过程中表现最佳,其损失下降速度更快,最终收敛效果也优于小参数模型。
这一趋势表明,较大的 GPT 模型能够更有效地从离线数据中学习复杂的决策模式,并展现出更强的拟合能力。
尽管较大模型在训练阶段表现良好,但更大的模型并不总是带来更好的决策性能。我们在三个交叉口决策任务上对不同规模的模型进行测试,并计算其决策成功率(Success Rate):
MTD-GPT(600K 参数) 在 左转、直行、右转 任务上的成功率分别为 66%、75% 和 94%。
当参数规模增加到 1.2M 时,决策成功率分别提升了 4%、8% 和 1%。
然而,当模型规模进一步扩大(>2.4M)时,决策成功率反而出现下降,特别是在左转和直行任务中,性能不如 1.2M 规模的模型。
这一实验结果揭示了 模型规模与泛化能力之间的权衡关系。尽管较大模型在训练数据上能够更快收敛,但其在 测试任务中的表现却未必最佳,甚至可能因过度拟合(Overfitting) 离线数据而导致泛化能力下降。
基于上述实验结果,我们得出以下结论:
更大规模的模型能够加速训练收敛,但并不一定能提升决策成功率。这一现象表明,仅仅依赖参数规模扩展并不能解决自动驾驶决策的所有挑战。
模型存在最佳参数规模区间。在本实验中,1.2M 规模的模型在多任务测试中取得了相对最佳的平衡,既能有效学习决策模式,又避免了过度拟合问题。
避免过度拟合是提升泛化能力的关键。如何在保持高学习能力的同时防止模型在固定数据集上的过拟合,成为影响自动驾驶 GPT 决策模型实际应用的核心挑战。
04 从离线模仿到在线进化:基于熵正则和策略微调的GPT模型持续进化
想象一下,如果一位司机只能按照教科书驾驶,从未经历过真实道路的变化与挑战,他能成为一位优秀的驾驶员吗?显然不能。同样,仅依靠离线预训练的决策GPT模型也面临着类似的局限性。
尽管基于海量数据的预训练让决策GPT模型获得了令人印象深刻的驾驶能力,但这种"纸上谈兵"的学习方式仍存在三个显著缺陷:
风格冲突:预训练数据包含各种驾驶风格和安全标准,就像同时向学员展示赛车手和老司机的驾驶方式,容易导致"身份混乱",在新任务上适应不良,甚至出现策略梯度崩溃(policy gradient collapse)。
安全顾虑:传统预训练方法未将安全性作为首要约束,模型可能会像一个只追求速度不顾安全的新手,在陌生路段做出超速、急刹等危险动作。
静态思维:预训练模型一旦定型就难以进化,缺乏持续学习能力,就像一个固执的驾驶员,即使面对新路况也拒绝调整自己的驾驶习惯。
为了解决这些挑战,我们提出了基于熵正则和策略微调的决策GPT在线自适应更新方法,让AI驾驶员能够在"实战"中成长。

图8 决策GPT微调流程
(1)安全护栏:约束马尔科夫过程建模


其中 d 是预设的安全阈值,就像驾驶考试的及格线,确保模型的累积风险不超过可接受范围。
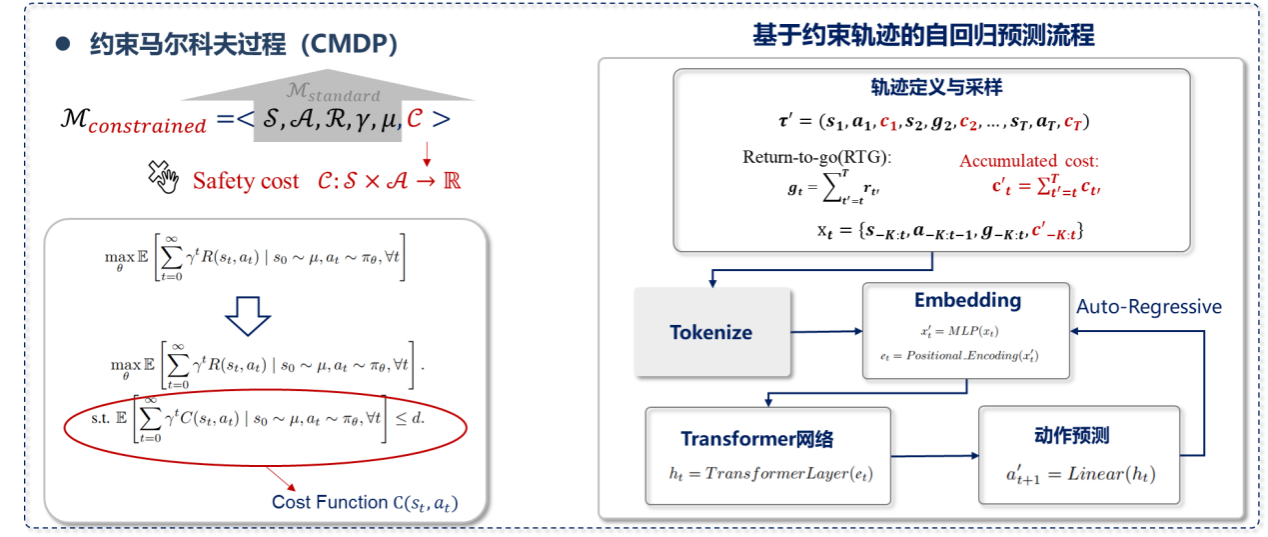
图9 CMDP过程建模
(2)探索与利用的平衡:序列建模中的熵正则化
在自动驾驶中,过于保守的策略可能错失最优路径,而过于冒险的策略则可能带来安全隐患。如何在确定性和探索性之间找到平衡?我们将策略 建模为条件多元高斯分布,就像一位驾驶员在面对各种情况时的决策倾向:

这个熵函数衡量策略的不确定性——高熵值意味着模型愿意尝试多种可能的动作(如新手驾驶员谨慎探索),低熵值则表示模型更倾向于确定性决策(如经验丰富的老司机)。
通过熵正则化,我们能够动态调整模型的探索-利用平衡,确保其在持续学习过程中既能吸收新知识,又不会忘记已掌握的技能,就像一位终身学习的专业驾驶员,既有坚实的基本功,又能灵活应对新挑战。这种基于熵正则和策略微调的在线进化框架,使得决策GPT模型不再是静态的"知识库",而是能够在实际驾驶环境中不断自我完善的"学习型驾驶员",为自动驾驶系统的安全性和适应性提供了双重保障。
(3)损失函数设计:探索与稳定的平衡艺术
在微调过程中,我们设计了一个特殊的损失函数,它就像模型学习的"指南针",引导模型在"模仿"与"探索"之间找到平衡。我们的核心目标是最大化策略的对数似然,同时保持一定程度的探索能力。具体来说,我们采用了熵正则化的负对数似然损失:

其中是拉格朗日乘子,用来平衡模仿学习与探索之间的权重。最终的损失函数表达为:
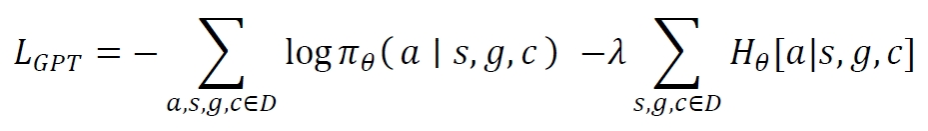
这个损失函数包含两个关键部分:
模仿学习部分:第一项引导模型学习专家的决策模式,就像学生跟随老师的示范。
探索保障部分:第二项确保模型保持一定的"决策多样性",防止它变得过于刻板,只会一成不变地重复相同的决策。
(4)优化策略:训练模型的智慧之道
在训练过程中,我们采用交替梯度优化方法,就像同时调整两个相互关联的旋钮:
策略参数θ与乘子λ将收敛到一个局部平衡点,实现稳定的学习。
4.3 在线微调框架:持续学习的闭环系统
我们提出的基于熵正则和策略微调的在线优化框架,构建了一个自我完善的闭环系统。这个框架包含以下步骤:
初始化预训练模型:加载在离线数据上训练好的决策GPT模型,并设置微调超参数。
环境交互:让当前模型在仿真环境中"驾驶",收集新的决策数据。
数据存储:将新采集的数据存入经验缓冲区,保证训练数据的与时俱进。
数据采样与训练:
- 从缓冲区均衡采样新旧数据
- 计算熵正则化损失函数
- 动态调整熵权重,平衡探索与稳定性
策略更新与迭代:更新模型后,重新收集数据并训练,形成"数据采集→经验存储→策略优化→策略更新"的闭环,直到模型性能收敛。
通过这一流程,决策GPT能够在保持原有能力的同时,适应新的环境约束,实现持续学习和优化。
4.4 实验结果:性能验证
为验证我们方法的有效性,我们选择了两个经典的模仿学习基线方法(BC和BAQL)以及仅进行预训练的决策GPT进行对比分析。实验在三种不同复杂度的交通场景中进行,每种算法在每个场景中进行了50次测试迭代。
图10 3个实验测试场景
实验结果展示了我们方法的优越性:
- 奖励表现:在场景1中,我们的方法和无熵正则化的GPT模型都优于基线方法。然而,在更复杂的场景2和3中,普通GPT模型表现下降,而我们的熵正则化方法依然保持最高奖励和最佳操作性能。
- 安全性能:在所有场景中,我们的方法始终实现最低的安全成本(即最少的安全违规),突显了其卓越的安全性能。相比之下,其他方法在不同场景中都表现出不同程度的不足。
特别值得一提的是,在最复杂的场景3中,我们的决策GPT模型表现出了明显的优势,证明了熵正则化在处理高度交互的复杂驾驶任务中的重要性。
这些结果有力地验证了我们提出的熵正则化决策GPT模型在自动驾驶决策系统中的有效性和鲁棒性。
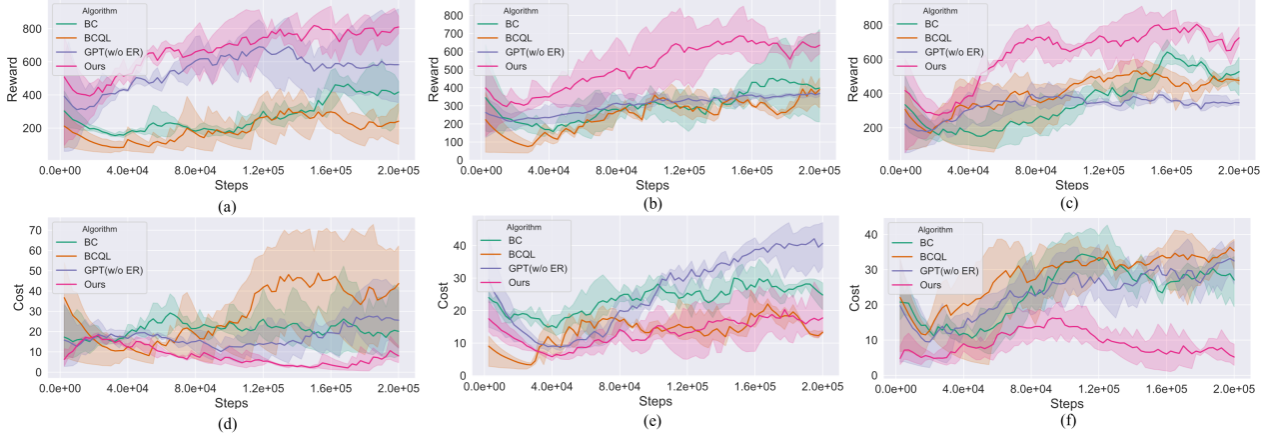
图11 实验结果分析
表 1 不同算法的性能测试表现
评价指标 |
BC |
BCQL |
GPT (w/o ER) |
Our Method |
|
场景 1 |
奖励 |
560.64 |
98.42 |
477.27 |
705.81 |
安全成本 |
41.61 |
10.92 |
22.54 |
8.06 |
|
场景 2 |
奖励 |
217.20 |
393.70 |
371.52 |
662.51 |
安全成本 |
23.19 |
16.60 |
44.78 |
15.94 |
|
场景 3 |
奖励 |
527.92 |
456.13 |
327.15 |
765.73 |
安全成本 |
30.42 |
37.60 |
32.23 |
5.79 |
05 未来展望:迈向更智能的决策基础模型
本研究构建了一个基于决策基础模型的自进化学习框架,针对高质量数据缺失、高效预训练模型架构设计和在线稳定自进化等挑战,设计了完整有效的训练流程。我们的方法有效提升了模型的任务泛化能力、持续学习能力、决策适应能力和稳定性。然而,面对复杂多变的现实决策场景,未来的优化空间仍然广阔。以下是我们对未来发展方向的展望:
当前研究主要依赖于模型或现实世界的轨迹数据。通过单纯模仿这些轨迹,决策模型往往只能"知其然"而不能"知其所以然"—它们缺乏人类所具备的深层逻辑推理能力,导致在复杂或两难情境中出现决策失效。未来可以从以下方面提升数据质量:
(1) 从大语言模型蒸馏推理能力:利用ChatGPT等性能卓越的大语言模型,蒸馏出高质量的逻辑推理数据。这将帮助决策模型从简单的"轨迹模仿"进阶到"思考模仿",真正提升其解决问题的能力。
(2) 构建情境-推理-决策链:收集不仅包含"做什么",还包含"为什么这样做"的完整决策链数据,让模型能够学习到决策背后的深层逻辑,而非仅仅模仿表面行为。
(3) 对抗性数据增强:构建更多棘手、边界和两难场景的数据,强化模型在极端情况下的决策能力。
这种从"蒸馏轨迹动作"到"蒸馏复杂逻辑推理能力"的转变,将使我们的决策模型更接近于具备真正思考能力的智能体。
当前的GPT 决策模型主要基于 Transformer 结构 进行自回归学习,而未来的自动驾驶决策模型需要进一步提升对多模态信息的理解能力,以增强实时性、泛化性和鲁棒性,这些方向可以是:
(1) 视觉-语言-行为统一架构:整合视觉语言模型(VLM)、视觉-行为模型(VLA)和多模态大模型(MLM)等技术,构建能够同时理解视觉、语言和行为信号的统一决策框架。
(2) 多级决策架构:设计包含战略层、战术层和执行层的多级决策架构,使模型能够同时处理长期规划和短期反应。
(3) 注意力增强机制:引入更先进的注意力机制,帮助模型在复杂环境中聚焦关键信息,过滤干扰因素。
(4) 因果推理增强:引入因果推理模块,使模型能够理解环境中的因果关系,而非仅仅依赖相关性进行决策。
持续学习能力是决策AI长期价值的关键。未来,以下方向将长期具有研究价值:
(1) 缓解灾难性遗忘:探索更先进的知识蒸馏、经验回放和参数正则化技术,确保模型在学习新任务的同时保留原有能力。
(2) 自适应学习率调整:开发能够根据任务难度和学习进度自动调整学习参数的机制,实现更高效、更稳定的学习过程。
(3) 不确定性感知更新:引入不确定性估计,使模型能够识别自身知识的边界,有选择地更新自身能力。
通过这些技术努力,我们的决策基础模型将实现更加稳定可靠的持续进化,逐步接近真正的"终身学习"智能体。我们期待未来的决策基础模型不仅能够模仿人类的行为,还能够理解行为背后的深层逻辑,实现真正的"知其然,知其所以然",为安全、高效的自动驾驶系统奠定坚实基础。
关于研究方法和实验设计的详细内容,可参考论文原文:
[1] Liu, J., Hang, P., Qi, X., Wang, J. and Sun, J., 2023, September. Mtd-gpt: A multi-task decision-making gpt model for autonomous driving at unsignalized intersections. In 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC) (pp. 5154-5161). IEEE.
[2] Liu, J., Zhou, D., Hang, P., Ni, Y. and Sun, J., 2023. Towards socially responsive autonomous vehicles: A reinforcement learning framework with driving priors and coordination awareness. IEEE Transactions on Intelligent Vehicles, 9(1), pp.827-838.
[3]Liu, J., Xu, C., Hang, P., Sun, J., Ding, M., Zhan, W. and Tomizuka, M., 2025. Language-driven policy distillation for cooperative driving in multi-agent reinforcement learning. IEEE Robotics and Automation Letters.
[4] Liu, J., Hang, P., Na, X., Huang, C. and Sun, J., 2024. Cooperative decision-making for cavs at unsignalized intersections: A marl approach with attention and hierarchical game priors. IEEE Transactions on Intelligent Transportation Systems.
[5] Liu, J., Hang, P., Zhao, X., Wang, J. and Sun, J., 2024. DDM-lag: A diffusion-based decision-making model for autonomous vehicles with lagrangian safety enhancement. IEEE Transactions on Artificial Intelligence.
电话:021-69583650 管理员邮箱:2015qgy@tongji.edu.cn
地址:上海市曹安公路4800号同济大学交通运输工程学院A440 邮编:201804
![]() TOPS课题组 页面浏览465,829次/访客70,123人次
TOPS课题组 页面浏览465,829次/访客70,123人次
{kind=link}